










https://hocassian.cn/wp-content/uploads/2020/05/b264453084509bec1535b65f8dc79c2cd5a3ff1b.jpg
翻译原文:《让二次元妹子动起来,用一张图生成动态虚拟主播》(译者:机器学习@Panda,网址:https://www.jiqizhixin.com/articles/2019-11-30-4)
英语原文:《Talking Head Anime from a Single Image》(作者:Google Japan@Pramook Khungurn)(网址:https://pkhungurn.github.io/talking-head-anime)


有多少人想要当个主播却因为害羞或对自己颜值不自信而放弃?也许虚拟主播和变声器能帮你实现梦想,但实际做起来却要困难得多。现在,Google Japan 的软件工程师 Pramook Khungurn 开发了一套基于深度学习的系统,只需一张正脸的动漫人物图,就能轻松合成各种面部和头部动作的动画,搭配人脸跟踪器等应用,能让人以很低的成本轻松制作动画主播节目,这也正是未来发展的方向:每个人都可以拥有自己的动态虚拟形象,每个人都可以成为主播,甚至携带着这个形象走入虚拟世界;而这种突破,所带来的商业潜力也是巨大的,就像十多年前QQ秀在聊天室的降临那样。

项目作者最喜欢的虚拟主播之一——Shirakami Fubuki。
我训练了一个可将动漫人物的脸做成动画的网络。
这种新网络能完成这样的工作:
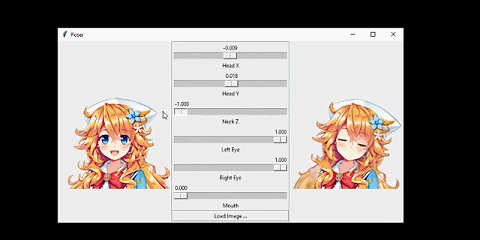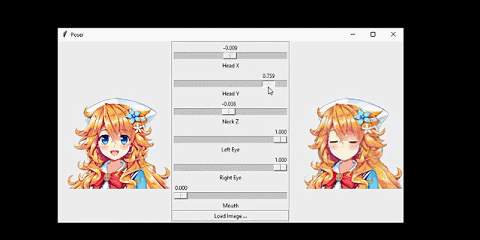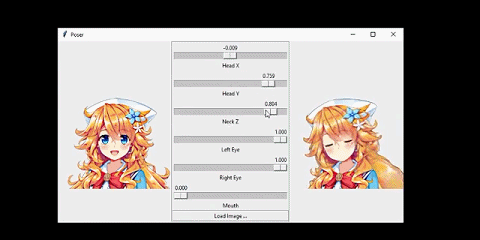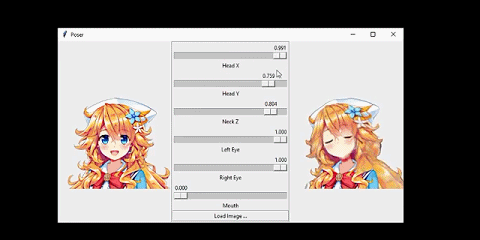
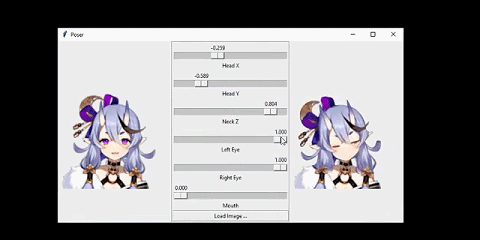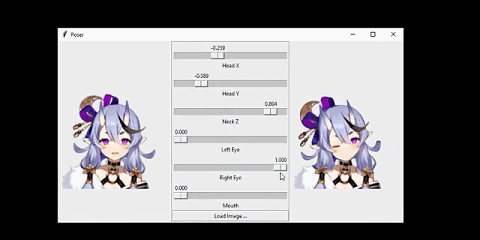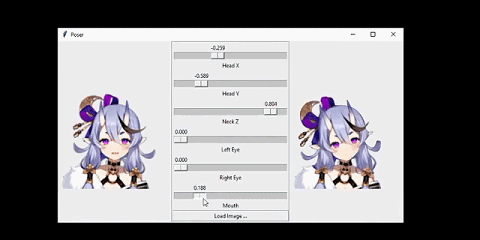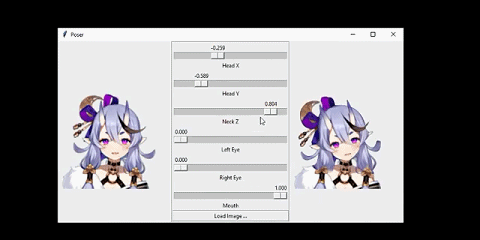
我将该系统连接到了一个人脸跟踪器上。从而让人物可以模仿我的头部动作:
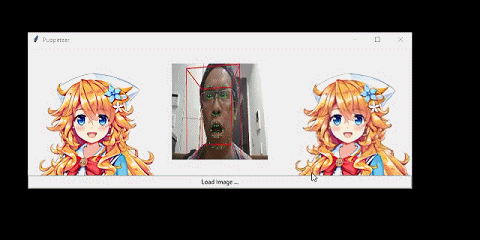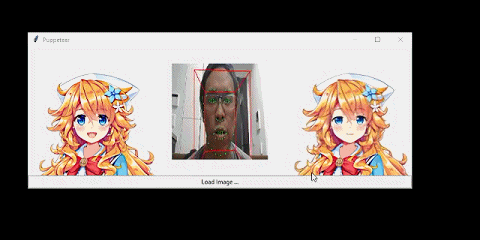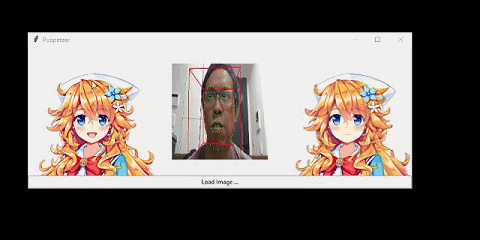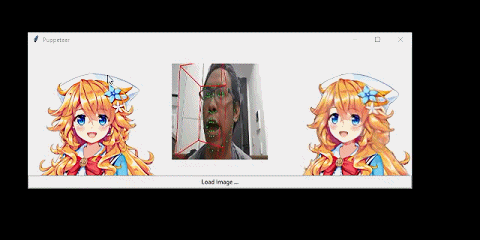
我也可以迁移已有视频中的人脸运动:

这个网络的输入是人物的正面图像,人物的姿势由 6 个数值指定。
我通过渲染 8000 个可下载的动漫人物的 3D 模型创造了一个新的数据集。
我使用的方法结合了之前两项研究。一是 Pumarola et al. 2018 年的 GANimation 论文《GANimation: Anatomically-aware Facial Animation from a Single Image》,我将其用于修改面部的特征(具体来说是闭上眼睛和嘴)。二是 Zhou et al. 2016 年根据外观流实现目标旋转的论文《View Synthesis by Appearance Flow》,我将其用于实现人脸的旋转。
概览
我想要解决的问题是这样的:给定某个动漫人物的一张人脸图像和一个「姿势(pose)」,生成同一人物的另一张图像,并且其人脸会根据姿势而变化。在这里,姿势是一个指定了该人物面部表情和头部旋转情况的数值的集合。具体来说,我的姿势有 6 个数值,分别对应前面动图中的不同滑块。我将在「问题设定」一节讨论输入和输出的细节。
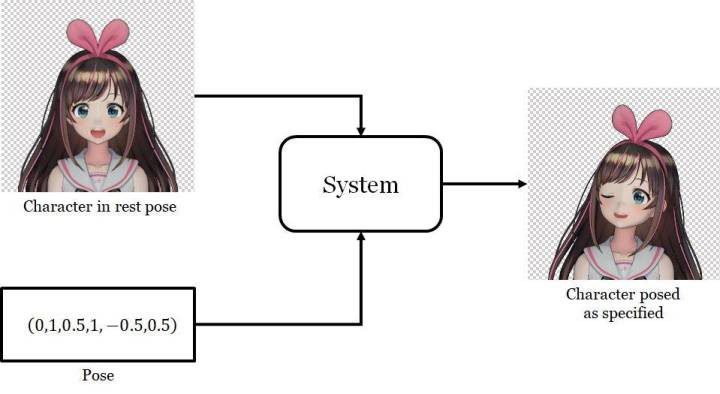
该系统的输入和输出
我使用了深度学习来解决这个问题。这需要我解答下面这两个问题:
- 我要使用什么数据来训练这个网络?
- 我要使用什么网络架构以及具体采用怎样的训练方法?
事实证明,第一个问题是最主要的挑战。我需要一个包含姿势标签的人脸图像数据集。EmotioNet 是一个包含所需类型的标签的大型人脸数据集。
但是,就我所知,还没有类似的动漫人物数据集。因此,我专门为本项目生成了一个新的数据集。
为此,我利用了这一事实:网上就有数以万计可下载的动漫人物 3D 模型,这些模型是用一款名为 MikuMikuDance 的 3D 动画软件创造的。我下载了大约 8000 个模型,然后使用了它们来渲染随机姿势的动漫人脸。详细的数据准备步骤将在「数据集」一节介绍。
我根据实现 3D 人物模型动画化的方法设计了该网络。我将这个过程分成了两步。第一步是改变面部表情;即控制眼睛和嘴的开闭程度。第二步是人脸旋转。
我为每一步都使用了一个单独的网络,并将第一个网络的输出用作第二个网络的输入。我将第一个网络称为人脸变形器(face morpher),第二个网络称为人脸旋转器(face rotator)。
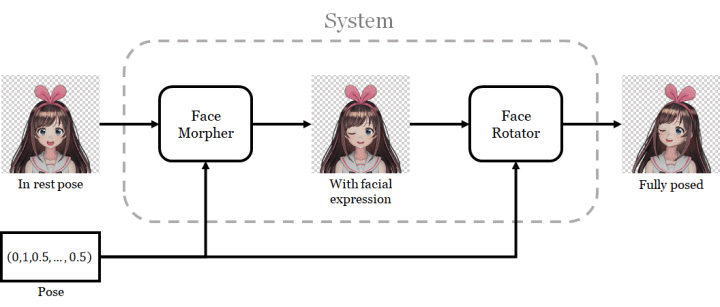
该系统的执行过程分为两个步骤
人脸变形器使用了 Pumarola et al. 的 ECCV 2018 论文中所用的生成器架构。
该网络可通过生成另一张包含对原始图像的修改的新图像来改变人脸表情。这些改变会通过一个 α 掩码与原图像组合,而这个 α 掩码也是由该网络本身生成的。我发现,这种架构在修改图像中的小部件方面表现非常出色:这里是闭上眼睛和嘴。
人脸旋转器则要复杂得多。我在单个网络中实现了两个算法来旋转人脸,因此该网络有两个输出。这两个算法是:
- Pumarola et al. 的算法。这就是刚刚用来修改面部表情的算法,但现在该网络的任务是旋转人脸。
- Zhou et al. 的视图合成算法。他们的目标是旋转图像中的 3D 目标。他们的实现方法是让神经网络计算一个外观流(appearance flow):这是一个映射图,能指示输出图像中的每个像素应该复制输入中哪个像素的颜色。
外观流能得到保留了原有纹理的清晰结果,但这种方法不善于描绘在旋转后变得可见的部分。另一方面,Pumarola et al 的架构得到的结果较模糊,但能描绘被遮挡的部分,因为其训练目标就是改变原始图像的像素,而不是从已有图像复制像素。为了将这两种方法的长项结合到一起,我训练了另一个网络通过一个 α 掩码将这两个输出融合到一起。这个网络还能输出「修整(retouch)」图像,即可将组合后的图像与另一个 α 掩码再组合起来。
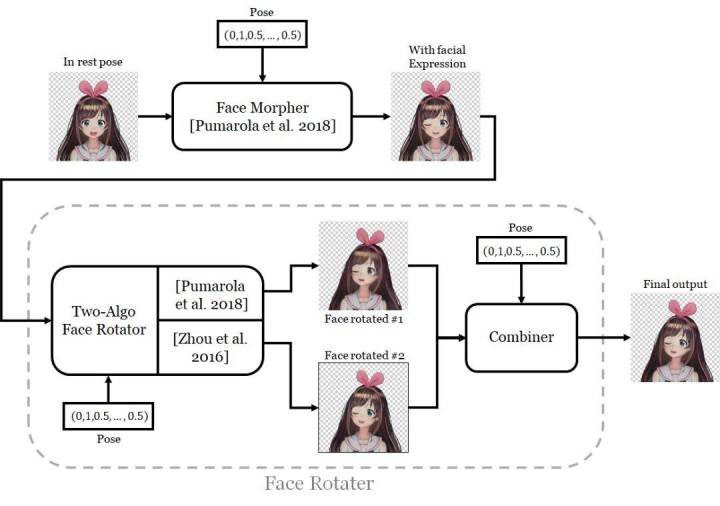
网络系统,这里更详细地展示了人脸旋转器
我将在「网络」一节详细讨论所有网络的架构和训练方式。
问题设定
如前所言,人物的人脸配置是通过姿势控制的。这里的姿势是一个 6 维向量,其中三个分量控制人脸特征,其取值范围为闭区间 [0,1]。
在这三个分量中,两个分量控制眼睛的睁闭:一个控制左眼,一个控制右眼。值为 0 时表示眼睛完全睁开,为 1 时表示完全闭眼。

另一个分量控制嘴的开合。但是,这个量为 0 时表示嘴完全闭上,为 1 时表示嘴完全张开。眼睛和嘴参数的语义互相抵触是因为这些 3D 模型的变形(morph)权重的语义就是如此:https://en.wikipedia.org/wiki/Morph_target_animation

6 维姿势向量中另外三个分量控制的是头部的旋转方式。用 3D 动画术语来说,头部是由一个「骨骼(bone)」连接的两个「关节(joint)」控制的。颈根(neck root)关节是脖子与身体相连的位置,颈尖(neck tip)关节则是脖子与头相连的位置。在人物骨架中,颈尖是颈根的延展。因此,应用于颈根的 3D 变换也会对颈尖产生影响,但反过来却不会。
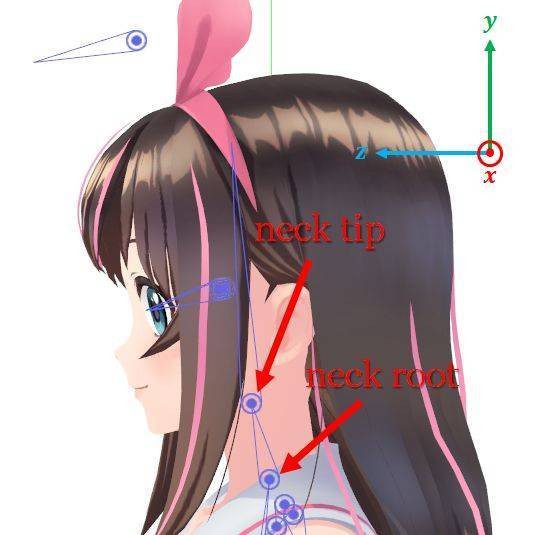
控制角色头部的两个关节



概括起来,输入是人物人脸的图像与一个 6 维姿势向量。输出是另一张姿势根据情况有所调整的人脸图像。
网络
如前所述,我的神经网络包含多个子网络。下面详细介绍它们。
人脸变形器
确定人物人脸的姿势的第一步是修改其人脸特征。更具体来说,我们需要人物能闭上眼睛和嘴。
Pumarola et al. 在他们的论文中描述了一种可以根据给定的动作单位(AU:Action Units,表示面部肌肉的运动)修改人脸特征的网络。
因为 AU 是非常通用的编码系统,所以他们的网络可不止能闭眼和闭嘴。因此,我觉得这能有效地处理我们手头上的任务。它没有让我失望。
但是,我没有使用该论文的所有方法,因为我的问题比他们的简单很多。尤其是他们的训练数据没有来自同一个人的表情不同的人脸对。因此,他们需要使用带有循环一致性损失的 GAN 来执行无监督学习。但是,我的数据是配对好的,所以我可以执行简单的监督学习。所以,我只需要他们的生成器网络。
下面我详细说说 Pumarola et al. 的生成器。下图是其架构示意图。
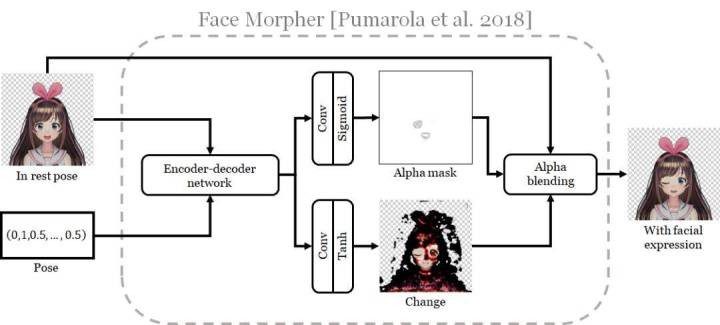
人脸变形器的架构。这是针对本案例对 Pumarola et al. 的论文中图 3 的复现
该网络会通过生成改变图像来实现对面部表情的修改,这个改变图像是原图像与一个 α 掩码(Pumarola et al. 称之为注意力掩码,但我这里使用了一个更常用的术语)的组合。要做到这一点,输入图像和姿势会被送入一个编码器-解码器网络,这会为输入图像的每个像素得到一个 64 维的特征向量。然后,这些特征向量构成的图像会经过两次不同的 2D 卷积单元和适当非线性的训练处理,得到 α 掩码和改变图像。附录 A.1. 给出了该网络的详细指标。
Pumarola et al. 使用了一个相对复杂的损失函数来训练他们的网络。让我惊讶的是,对我的问题来说,简单的 L1 像素差异损失就足够了。这个损失函数的数学描述如下:
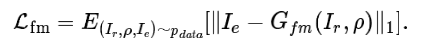
我使用了与 Pumarola et al. 一样设置的 Adam 算法来优化网络:学习率 1^−4、β_1=0.5、β_2=0.999,批大小为 25。网络训练了 6 epoch(3 000 000 个样本),在我的 GeForce GTX 1080 Ti GPU 上耗时两天。
人脸旋转器
人脸旋转器由两个子网络构成。双算法旋转器使用两个不同的算法旋转人物的面部,其中每个算法都有各自的优势和短板。为了将两者的优势结合到一起,还有一个组合器(combiner)能使用一个 α 掩码将两个算法输出的图像融合到一起,并且还能对图像进行修整,实现质量提升。
双算法旋转器
下图描述了其架构,附录 A.2. 给出了详细说明。
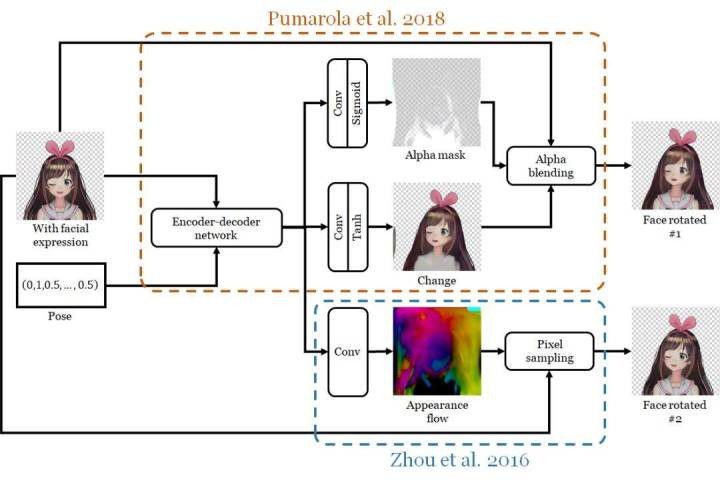
可以将该网络看作是对 Pumarola et al. 的生成器的扩展:其包含该生成器的所有单元,还多了一个新的输出路径。原有的路径的任务只是旋转人脸,而不是闭上眼睛和嘴。新的路径则是使用了 Zhou et al. 论文中描述的方法来旋转目标。
其中的思想是:物体旋转(尤其是角度较小时)很大程度上涉及到将输入图像内的像素移动到不同位置。因此 Zhou et al. 提出计算外观流:这是一种映射图,能指示输出图像中的每个像素应该复制输入中的哪个像素。然后,这个映射图和原始图像会被传递给一个像素采样单元以生成输出图像。在我的架构中,外观流就是简单地通过将编码器-解码器网络的输出传递给一个新的卷积单元而计算的。
我在训练网络时使用了两个不同的损失。第一个就是简单的 L1 像素差异损失:
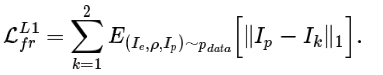
第二个损失是 L1 像素差异损失和 Johnson et al. 的感知特征重建损失的和:
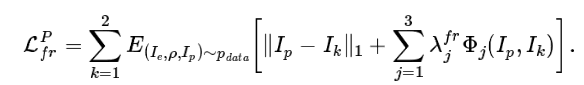
同样,优化用的是 Adam,使用了与人脸变形器一样的超参数。一共训练了 6 epoch(3 000 000 个样本)。当使用 L1 损失时,我将批大小设为 25,训练同样用去了大约两天时间。但是,由于评估特征重建损失需要远远更大的内存,所以当使用这种感知损失进行训练时,我必须将批大小降至 8。在这种情况下训练也用去了 6 天。
组合器
看看下面双算法旋转器的输出,可以看到单独任何一个算法的结果都不够好。
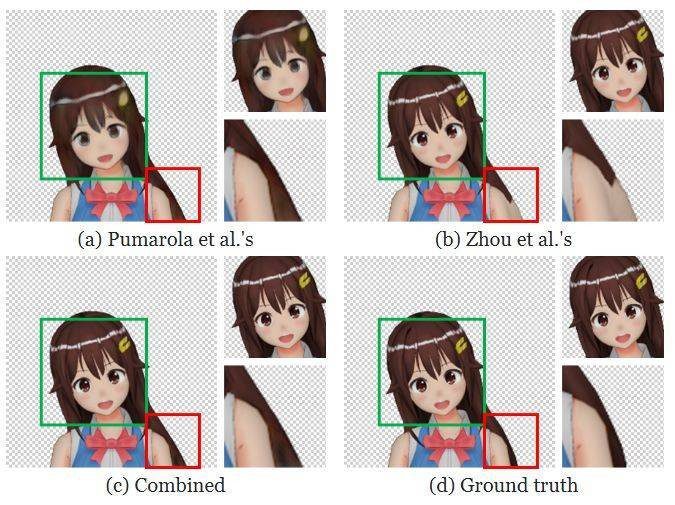
使用不同算法将人物的脖子向右旋转 15°
使用不同算法将人物的脖子向右旋转 15°
上图展示了对人物脖子进行旋转操作的情况,旋转后她一部分原本被遮挡的长发会变得可见。可以看到,Pumarola et al. 的算法会得到模糊的人脸。我推测原因是该网络需要根据压缩的特征编码生成所有新像素,这可能会丢失原图像中的高频细节。之前其它一些编码器-解码器架构的研究也观察到了类似的行为,比如 Tatarchenko et al. 和 Park et al.。
Zhou et al. 则是复用输入图像的像素,因此能够产生清晰的结果。然而,通过复制已有像素难以重建之前被遮挡的部分,尤其是所要复制的位置距离很远时。在上图 b 中可以看到,Zhou et al. 的算法使用了手臂的像素来重建去除遮挡后的头发。另一方面,Pumarola et al. 方法得到的头发颜色更自然。
通过组合这两个算法的输出,我们可以得到好得多的结果:可见像素调整位置后会保持原有的清晰度,去除遮挡部分的像素也能获得自然的颜色。下图展示了组合器网络的架构,详情参阅附录 A.3.
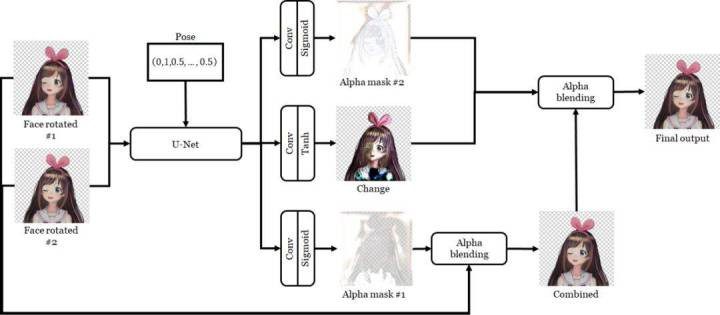
组合器的架构
这个组合器网络的主体是 U-Net,这有助于对每个像素进行操作。然后它的输出会被变换成两个 α 掩码和一张变化图像。其中第一个 α 掩码会被用于组合两张输入图像。然后,第二个 α 掩码和变化图像则会与前一步的输出组合,得到最终结果。最后一步是对组合得到的图像进行修正,以提升其质量。
为了减少内存用量,这个组合器是与双算法旋转器分开训练的。我在所有训练样本上运行了后者,从而生成前者的输入。同样,我实验了两个损失函数。第一个是 L1 损失。
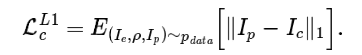
第二个是感知损失:
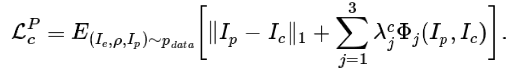
这个训练流程类似于人脸变形器的训练过程。但是,为了方便,这个训练仅进行了 3 epoch,而非 6 epoch。使用 L1 损失时批大小为 20,训练消耗了一天时间。使用感知损失时,批大小为 12,训练持续了两天时间。
评估
定量评估
表现评估使用了两个指标。第一个是网络的输出与基本真值图像之间的平均每像素均方根误差(RMSE)。第二个是平均结构相似度指数(SSIM)。分数使用测试数据集中的 10 000 个样本计算得到。
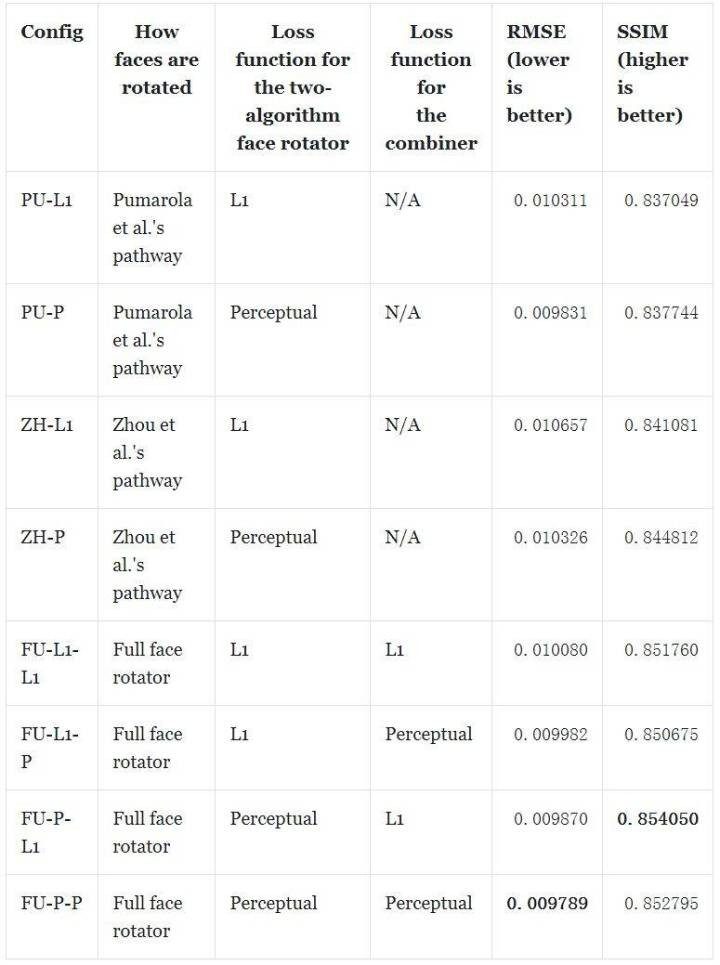
可以看到,仅使用一个人脸旋转路径的表现通常比组合使用两个路径的表现差。一个值得关注的例外是 PU-P,其在 RMSE 上的表现优于除 FU-P-P 之外的所有网络。但是在 SSIM 指标上,组合的效果总是更好。
还可以观察到另一个趋势:使用感知损失时通常在两个指标上都表现更好。但是,在 SSIM 指标上表现最佳的配置是 FU-P-L1 而非 FU-P-P。
看起来最佳的配置是 FU-P-L1 和 FU-P-P,这两者在这两个指标上都取得了第一和第二名的成绩。因此,我们需要进一步检查生成的图像才能确定哪个更好。
定性评估
下面展示由一种配置生成的结果。

由 FU-P-P 网络配置渲染的人物动画
我们从视觉质量方面比较一下各种网络配置。PU-L1 和 PU-P 得到的结果过于模糊,质量差。这表明虽然 Pumarola et al. 的架构能有效地修改面部上的小组件,但当需要修改图像中较大部分时,其效果并不好。还可以观察到,由于使用了感知损失,所以 PU-P 得到的结果更清晰。但是,这种损失的副作用是会产生棋盘状伪影。

PU-L1 和 PU-P 生成的图像
ZH-L1 和 ZH-P 则能得到非常清晰的结果,因为它们是直接复制输入图像的像素。但是,它们可能生成会让人物变样的不规则伪影。

ZH-L1 和 ZH-P 生成的图像
对于使用了所有子网络的配置,面部和身体的大部分区域都很清晰,因为这些像素是由组合器从 Zhou et al. 的路径选取的。因为 Pumarola et al. 的路径比 Zhou et al. 的更不容易复制近邻像素,所以组合器可以从前者的像素中进行选择,很大程度上(但并非完全)消除后者产生的扰动伪影。因此,完全配置的网络比仅使用一条路径的网络能得到质量更好的图像。但是,这些输出中消除遮挡的部分依然很模糊。下图表明,在 4 种完全的配置中,FU-P-P 得到的结果最清晰。但是,某些人(包括我)可能并不喜欢棋盘状伪影,而更偏爱 FU-P-L1 的更平滑的输出。

FU-L1-L1、FU-L1-P、FU-P-L1、FU-P-P 生成的图像
我注意到所有网络似乎对人物的身体结构都有一定程度的高层面理解。举个例子,大和伊织(Yamato Iori)的右眼被头发挡住了,当她闭眼时,任何网络都不会去移动她的头发。但是,我们也观察到一些因为图像解析不正确而导致的失败案例。比如夜樱多摩(Yozakura Tama)有一条挂在身前的长发辫。所有网络配置都将其看作是两部分,在移动头时仅移动了其中的上部分。衣服和配饰也可能被误认为是头部的一部分,见下图。
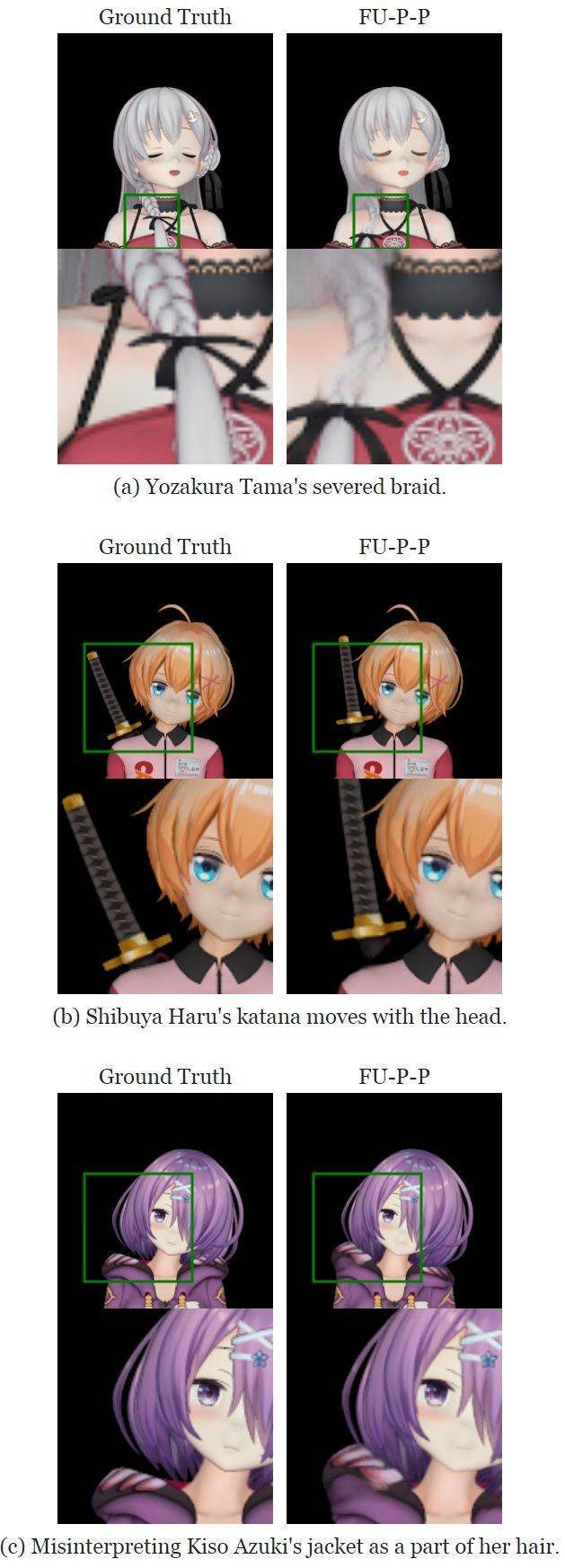
由于图像解析不正确而导致的失败案例
总的来说,FU-P-L1 和 FU-P-P 应该是最佳的网络配置,因为它们能在不产生大规模伪影的情况下生成基本上清晰的输出。FU-P-P 生成的图像更清晰,但却有棋盘状伪影,FU-P-L1 得到的结果更模糊但更平滑。但这两个网络在解析输入图像时都可能出错,从而得到身体结构/物理结构上不可信的动画。
绘制动画
本项目的最终目标是将非 3D 渲染的图画变成动画。我使用最佳的网络 FU-P-P 评估了我的方法的表现,评估使用了 Nijisanji 旗下虚拟主播的动漫图像和 Waifu Labs 生成的人物。下面展示了 16 个人物的动画:

因为网络是在渲染过的动画人物上训练的,所以他们能很好地应用于同一艺术风格的绘画。需要指出,网络在处理眼睛方面的表现尤其好。对于大多数人物,他们都能正确地闭上眼睛,即使眼的一部分被头发遮挡时也是如此。
GANimation 论文:https://www.albertpumarola.com/research/GANimation/index.html
根据外观流实现目标旋转的论文:https://arxiv.org/abs/1605.03557
完整版博客介绍:https://pkhungurn.github.io/talking-head-anime/
既然可以把照片转为动态组件了,那么自定义的,独一无二的动漫形象呢?接下来让我们看看Gwern大神通过英伟达StyleGAN生成的动漫头像吧~(以下文段转自 栗子@凹非寺)

△用二次元妹子数据培育的StyleGAN
对一只GAN来说,次元壁什么的,根本不存在吧。
你看英伟达的StyleGAN,本来是以生成逼真人脸闻名于世。

不过,自从官方把算法开了源,拥有大胆想法的勇士们,便开始用自己的力量支配StyleGAN,顺道拯救世界。
以前,你的老婆可能是绫波丽,可能是真白,可能是漩涡鸣子 (误) 。

而今,推特名叫roadrunner01的程序猿,给StyleGAN喂食了大量二次元女子图像。 然后,AI生成了从萝莉、到乙女、到御姐的 (各种) 变换过程。里面的每一帧,都可以是你的选择:

发色和发型,眼睛里的神色,都在一刻不停地变化。 但任它千变万化,妹子依旧浑然天成。不论色彩,还是五官之间的配合,都有骄人的默契。

如果,你喜欢收到两颊泛红的讯号:

或者,你只喜欢清新的邻家少女:

还是,性别特征不够明显的幼女呢:

不管怎样,红瞳才是正义。

Reddit网友发出了很客观很中肯的赞叹:
△注释:waifu=wife 相比之下,推特网友就更加直白一些:
要用怎样的数据集? 虽然,roadrunner01并没有透露,他的StyleGAN到底吃了怎样的数据集,我们只感受到美少女战士强大的基因;

△我认得你的额头 不过,另有一位叫做gwern的程序猿,也用二次元数据训练了StyleGAN,并且公开过自己的数据集。 鉴于他的训练成果同样秀色可餐:

△来自gwern的StyleGAN 且这位程序猿的老婆是明日香:

△来自gwern的StyleGAN 我们就来观察一下,这只AI到底吃过怎样的数据。 数据集名叫DANBOORU2018,包含超过330万张图,超过9970万个标签:

△为了安全,只截取了比较安全的部分 不出所料,是个百无禁忌的StyleGAN了。 为何不出所料?回头再看roadrunner01的作品,也有许多妹子穿着十分客气,可以欣赏到曼妙的锁骨,甚至香肩:

△来自roadrunner01的StyleGAN 想要数据集的同学,请使用文底的传送门。
想要,就自己去训练啊。 我训练好的StyleGAN二次元模型,你也直接可以下载啊。 想要,就自己去训练啊。 我训练好的StyleGAN二次元模型,你也直接可以下载啊。 传送门见文底。 StyleGAN原理是什么? 数据集有了,就来看看StyleGAN是怎样工作的吧。 它之所以获得“GAN 2.0”的盛赞,就是因为生成器和普通的GAN不一样。 这里的生成器,是用风格迁移的思路重新发明的。

△把B的风格,迁到A头上 向AI输入两张图,图A决定人物的年龄、性别、头发长度和姿势;图B决定一切其他因素:肤色、发色、衣服颜色等等。 这样一来,图B的画风,就可以自然地转移给图A。 更重要的是,StyleGAN可以从粗糙、中等、精细三种尺度上调节图像的生成:


△上为粗糙,下为中等 粗糙尺度,是规模最大的调整,人脸的朝向、脸型和发型,都在这里调整;中间尺度,调整只会涉及脸部特征、发色发量了。

△精细尺度 精细尺度,改变的是图像的配色,几乎不会给任务变脸了。 三者组合在一起,才有最终的生成效果。 不过,私以为配色才是最重要的:

你看,这些蓝妹子多可爱:

△来自roadrunner01的StyleGAN 那么,StyleGAN算法已经开源了,330万张的数据集也有了。 想要生成老婆的话,可以开始训练了。 不想训练的话,用gwern训练好的模型直接生成也行啊。

△来自roadrunner01的StyleGAN 悄悄告诉你,如果你不想生成老婆,却想生成猫片,可以直接用官方提供的预训练模型哟。

△这是一群假猫,不是数据集 DANBOORU2018
二次元妹子数据集: https://www.gwern.net/Danbooru2018
英伟达StyleGAN官方实现: https://github.com/NVlabs/stylegan gwern
训练好的二次元StyleGAN模型: https://drive.google.com/file/d/1z8N_-xZW9AU45rHYGj1_tDHkIkbnMW-R/view StyleGAN
论文传送门: https://arxiv.org/abs/1812.04948




https://www.bilibili.com/read/cv4212136科技, 人工智能, AI, 机器学习, 生成, 虚拟主播, Vtube