










https://hocassian.cn/wp-content/uploads/2020/05/55d44aeb5c245da971a5ff067bf2b5c689aceb32.png
前几天同和君被某粉丝吐槽不务正业,那今天咱们就来务一下正业,来简单讲讲有关SQL Server的基础操作(其实是为了交差)。

有关SQL(结构化查询语言)与其对应的各类数据库管理系统(SQL Server、Access等)的功能与运用范围,在这里就不做赘述了,有兴趣的可以去搜一下,然后你就会发现一个新的世界了~
首先下载安装SQL Server并配置其实例,这方面也不详细说明了,有点电脑基础的都会~然后就是正式的实操环节,首先连接到服务器:
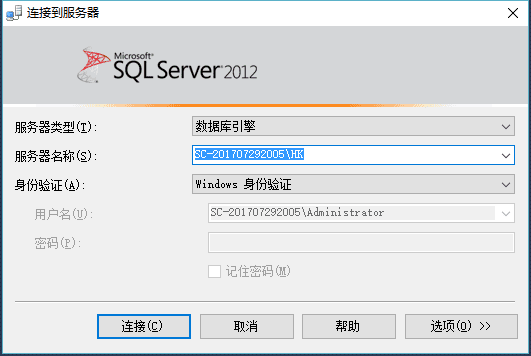
进入后第一件事当然是创建属于自己的数据库啦~
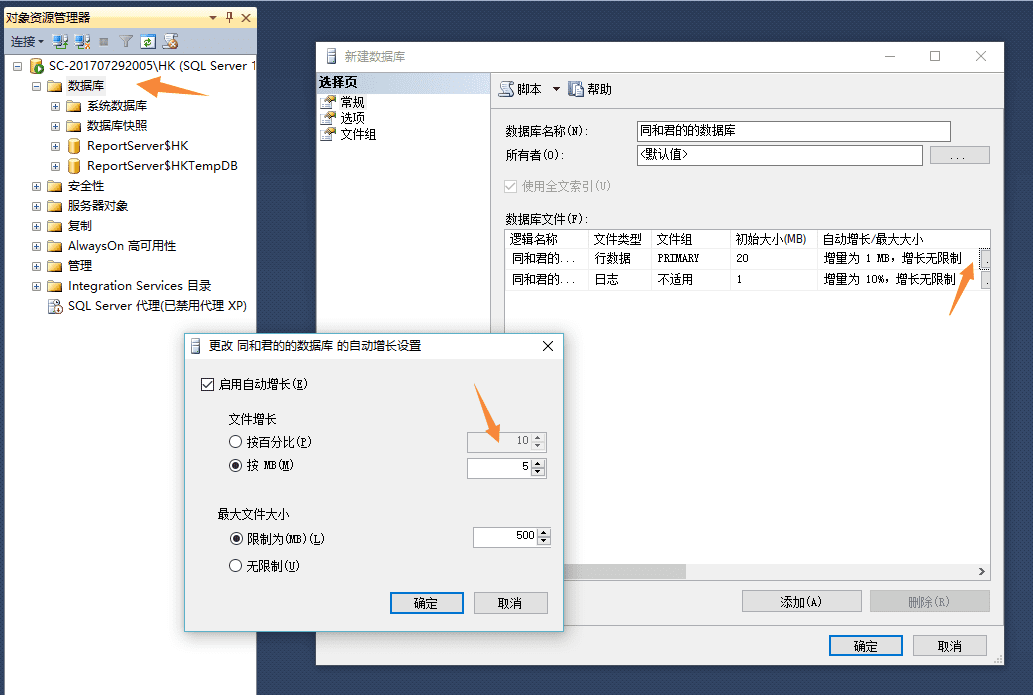
右键「数据库」,选择新建,然后跳出右边的对话框,根据实际需求来设置「文件初始大小」、「文件增长量」、「日志初始大小」、「日志增长量」。
增长方式和文件大小上线可以自定义。
确定后就能看的建立好的数据库了。
试着生成一个有关数据库信息的脚本~
详细sql文件信息如下:

当然你也可以选择使用Transact-SQL语言直接来创建数据库:
先点「新建查询」调出查询分析编译器:
然后输入以下语句:
create database HKSDB
on
primary
(name=HKSDB_data,
filename='d:FileTEMPHKSDB_data.mdf',
size=20MB,
maxsize=500MB,
filegrowth=5MB)
log on
(name=HKSDB_log,
filename='d:FileTEMPHKSDB_log.mdf',
size=20MB,
maxsize=100MB,
filegrowth=1MB)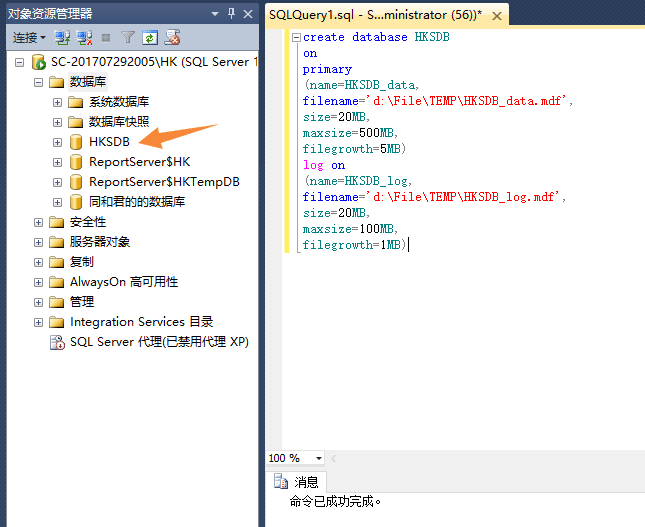
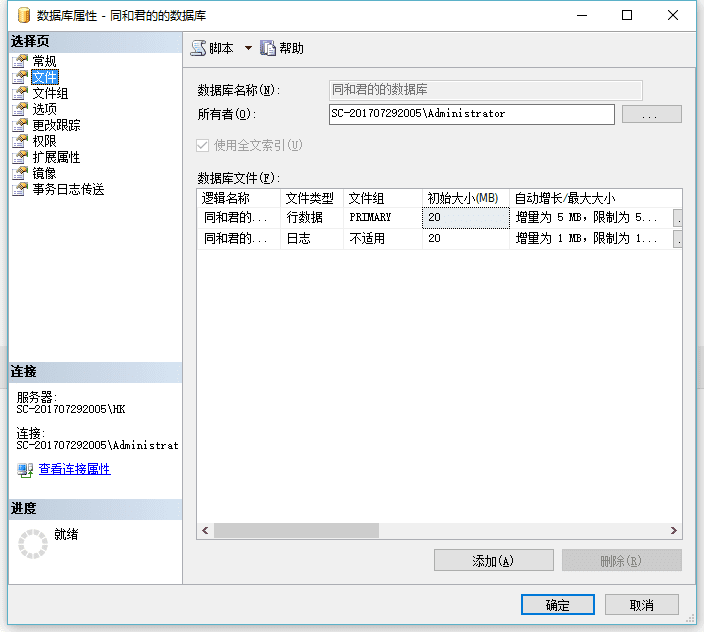
右键相应的数据库属性会跳出很多选项:
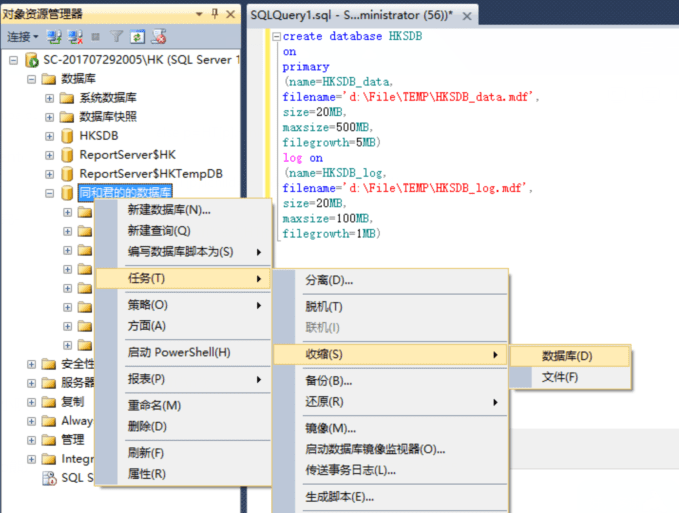
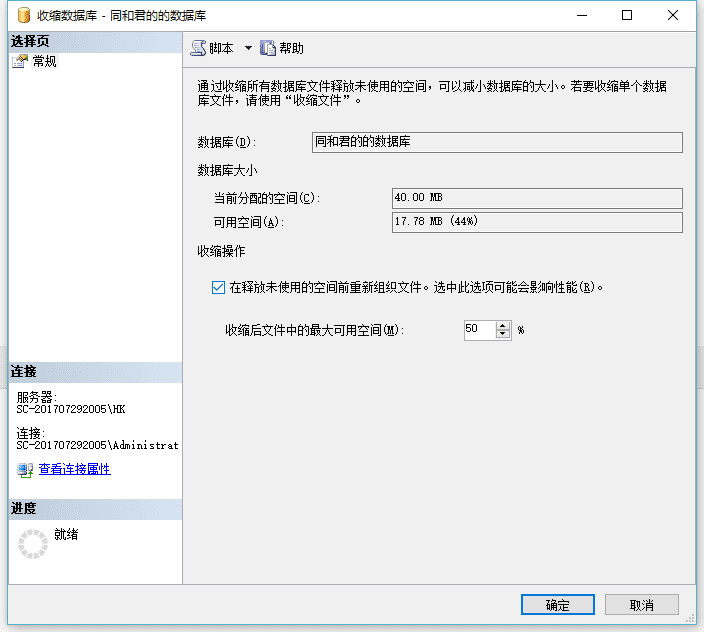
如果你把数据库的初始值设高了,可以通过收缩来减小:
接着是通过代码来查看&修改数据库属性:
--查看数据库属性
sp_dboption HKSDB
--查看数据库信息
sp_helpdb HKSDB
--修改日志文件的最大值和初始值
/*
将HKSDB_log日志文件的最大值改为200MB,初始值改为40MB
*/
use HKSDB
go
alter database HKSDB modify
file(name=HKSDB_log,maxsize=200MB)
alter database HKSDB modify
file(name=HKSDB_log,size=40MB)
--更改数据库
/*
为数据库HKSDB添加一个辅助文件,文件名为HKSDBFZ,存储在D:FileTEMPHKSDBFZ.ndf中,初始大小为2MB,最大值为10MB,增长量为1MB。同时为数据库HKSDB添加一个日志文件,文件名为HKSDBLOG1,存储在D:FileTEMPHKSDBLOG1.ldf中,初始大小为1MB,最大值为5MB,增长量为1MB。
*/
use HKSDB
alter database HKSDB
add file
(name=HKSDBFZ,
filename='D:FileTEMPHKSDBFZ.ndf',
size=2mb,
maxsize=10mb,
filegrowth=1mb)
alter database HKSDB
add log file
(name=HKSDBLOG1,
filename='D:FileTEMPHKSDBLOG1.ldf',
size=2mb,
maxsize=10mb,
filegrowth=1mb)
/*
删除数据库HKSDB中的辅助文件HKSDBFZ和日志文件HKSDBLOG1。
*/
use HKSDB
alter database HKSDB
remove file SYDBFZ
alter database HKSDB
remove file HKSDBLOG1
如果你对某个数据库不爽,想把它打入冷宫,可以直接右键数据库删除,也可以手动输入代码:
use HKSDB
drop database HKSDB似乎碰上了钉子户:

试试大神的代码:
USE MASTER
GO
DECLARE @dbname SYSNAME
SET @dbname = '同和君的的数据库' --这个是要删除的数据库库名
DECLARE @s NVARCHAR(1000)
DECLARE tb CURSOR LOCAL
FOR
SELECT s = 'kill ' + CAST(spid AS VARCHAR)
FROM MASTER..sysprocesses
WHERE dbid = DB_ID(@dbname)
OPEN tb
FETCH NEXT FROM tb INTO @s
WHILE @@fetch_status = 0
BEGIN
EXEC (@s)
FETCH NEXT FROM tb INTO @s
END
CLOSE tb
DEALLOCATE tb
EXEC ('drop database [' + @dbname + ']') 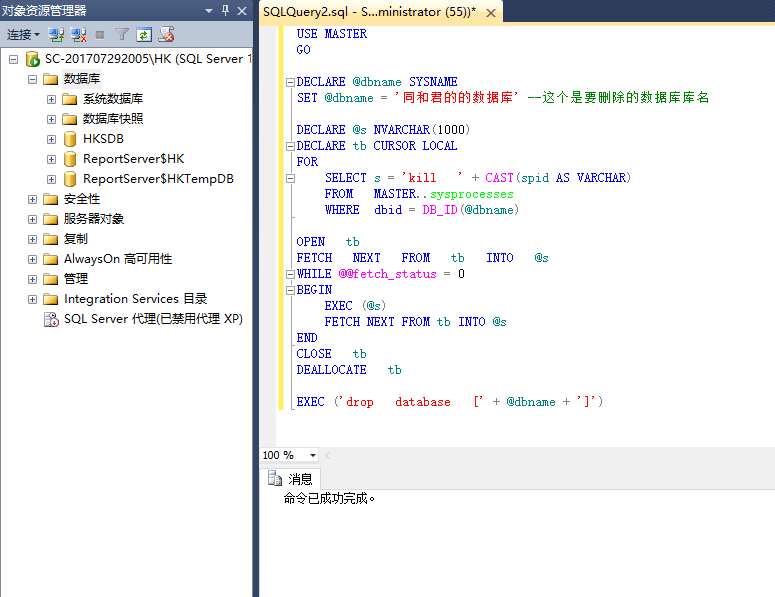
完美~
好的,那么到这里大家已经大致了解了数据库的定义与管理,接下来带大家起飞了~
手动一个个创建数据表是一件很苦逼的事情,再加上我们还没学到JAVA和SQL Server链接的JDBC技术,所以同和君选择一种取巧的方式:从Excel表格直接导入数据~
选好数据源类型:
选好目标文件后下一步:
然后对目标表的各项数据分别选好类型(其中大多都系统默认好了,局部地区稍微修改下就好,比如学号之类的):
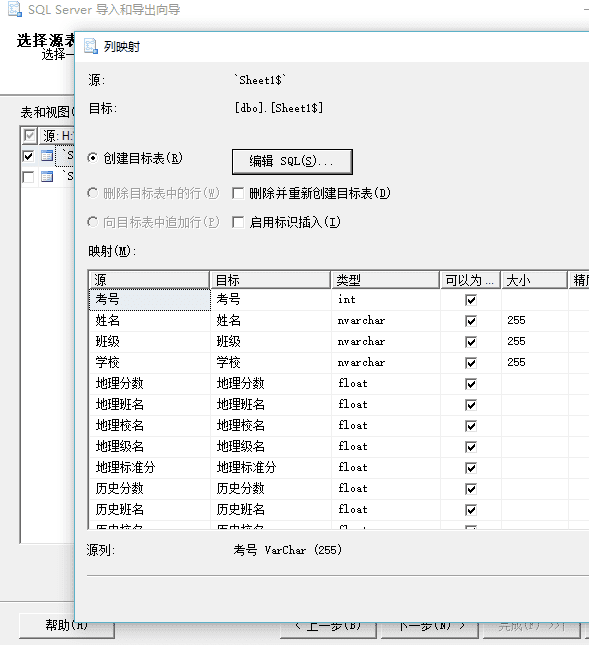
我们来预览一下~
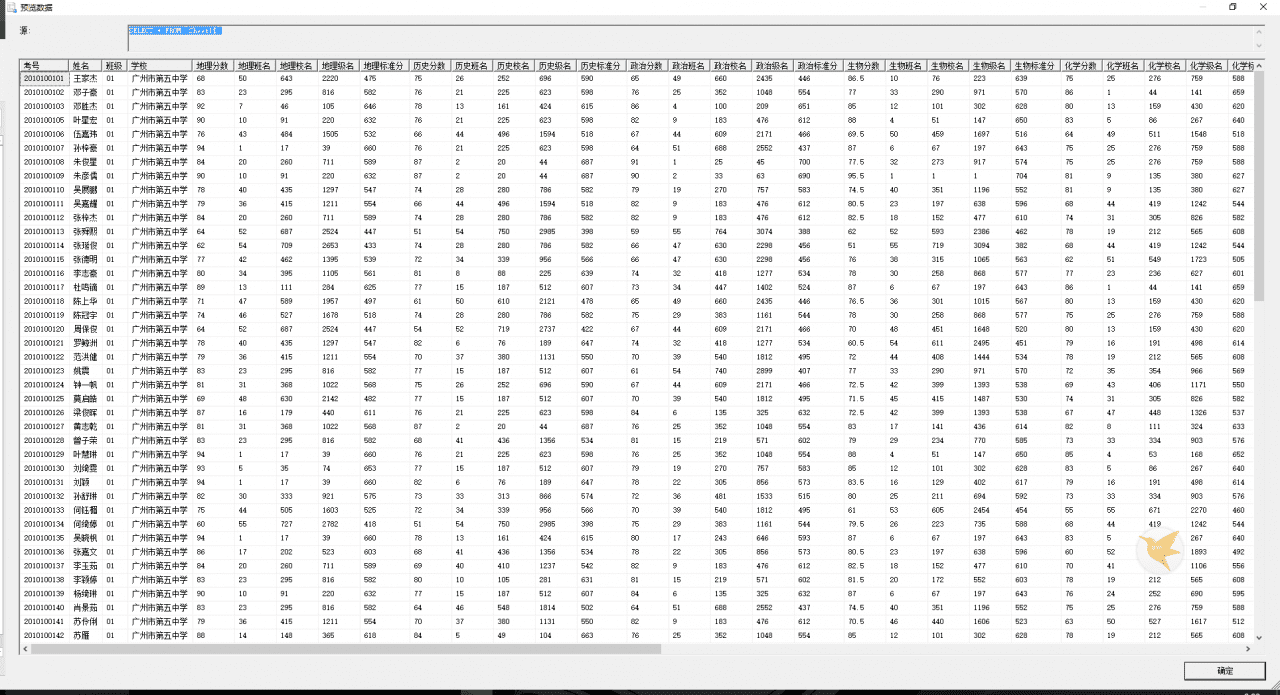
成功~
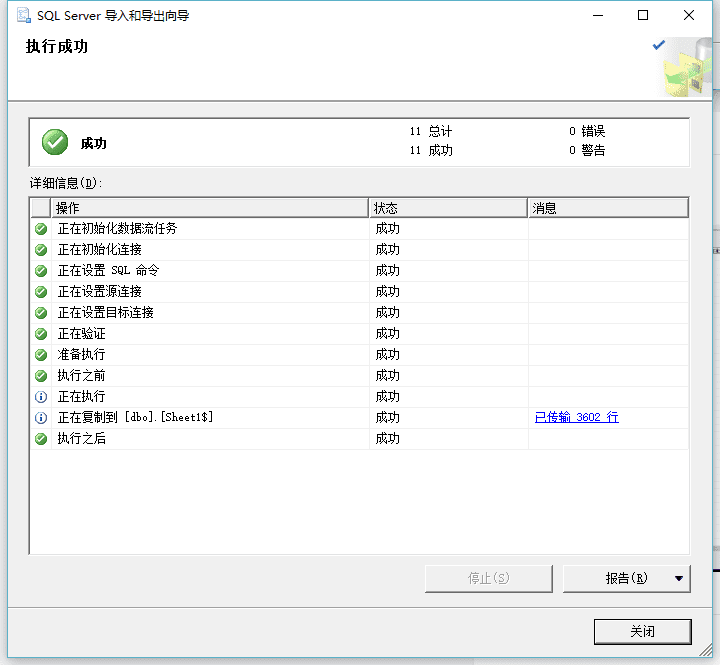
然后我们可以开始骚操作了~
不过在此之前,还是先教大家如何备份&还原吧~
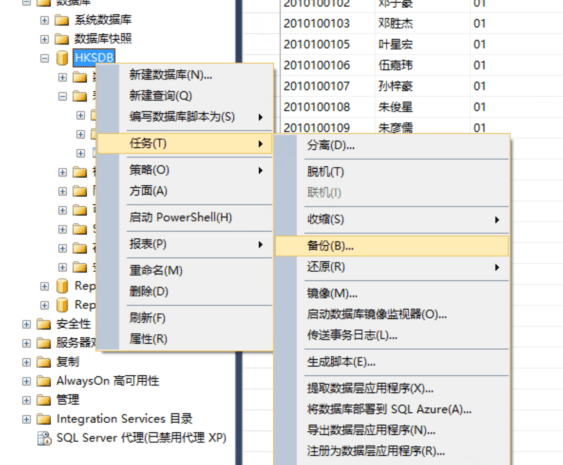
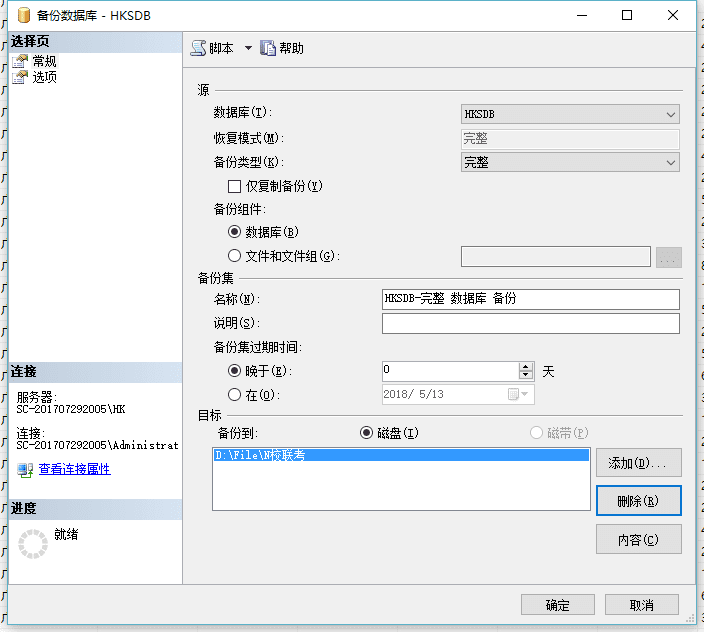
接下来是还原,这回我们导入一个不同的~
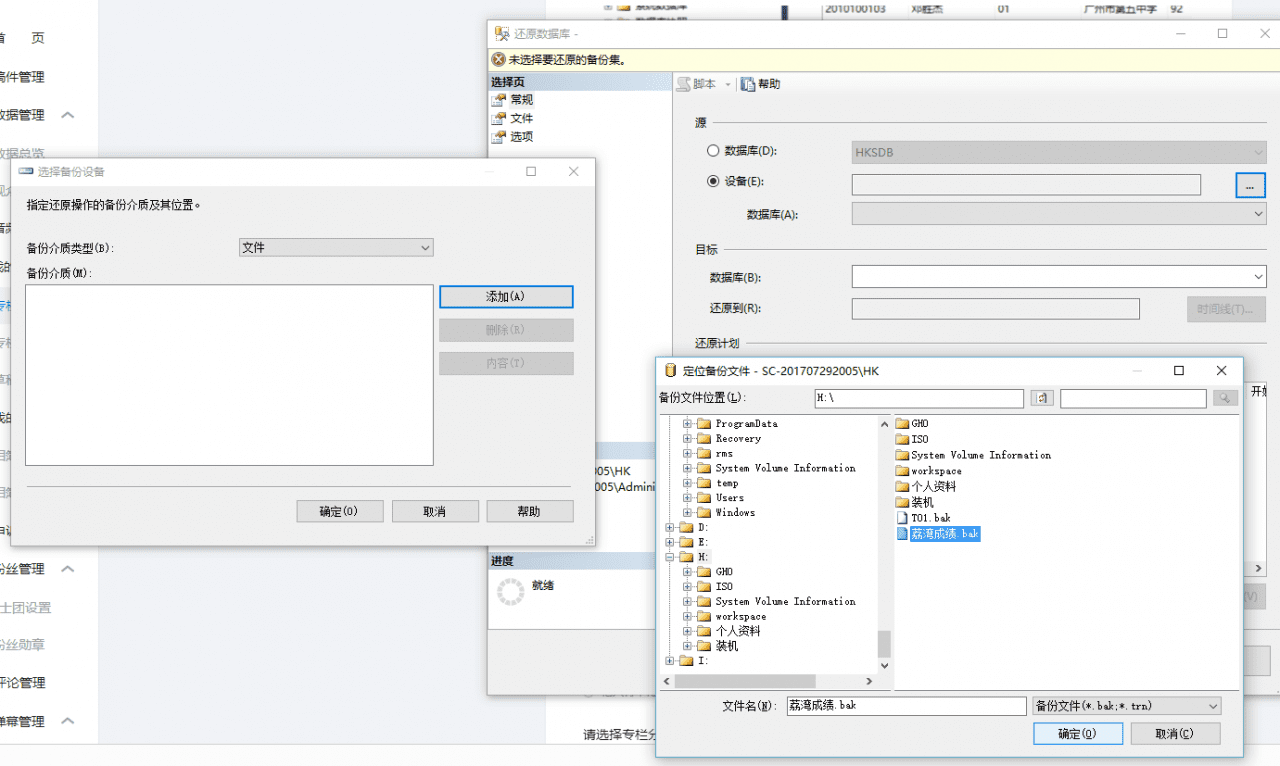
这个是我用来做多表连接的~详细的后边会讲到~

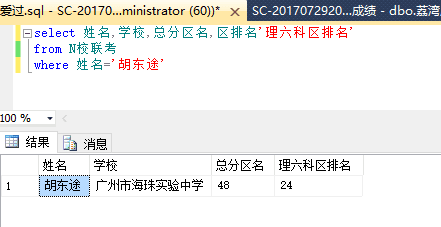
首先我们来查一下同和君初恋女孩高一的成绩:

然后保存该sql文件:
然后再查一下初中好基友的总分区排名:
再保存下:
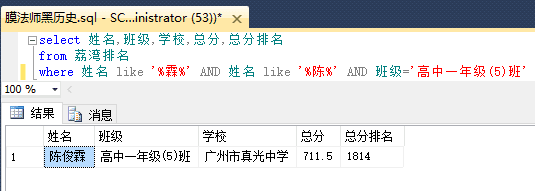
然后查一下b站up主@SmartMogician 的黑历史
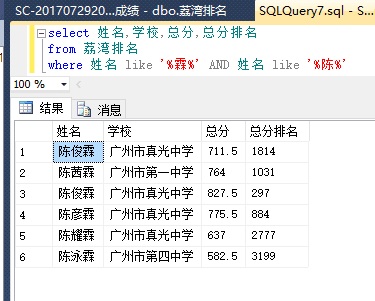
哟,竟然出现同校同学同名同姓的情况了!
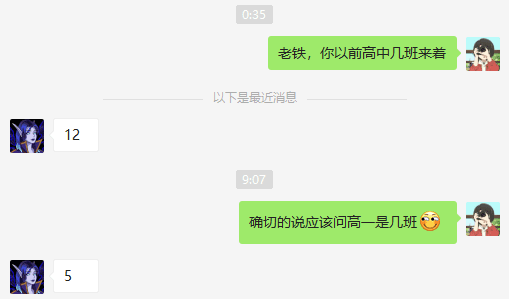
这样的话就能成功筛选了:
没想到当年的语文竟然这么难!
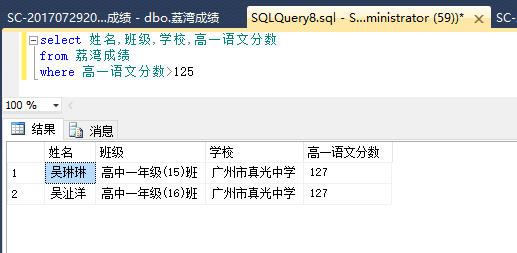
当年的学霸……
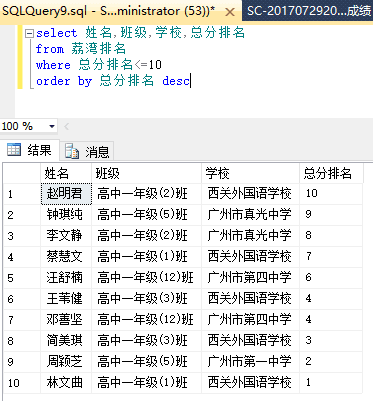
这样看可能更直观:
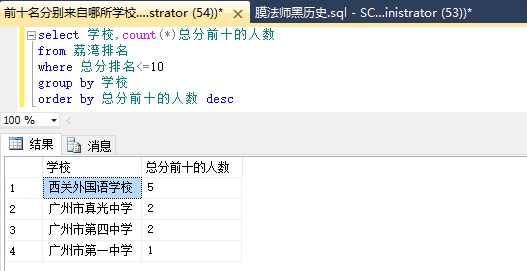
(emmmm……这真的不是招生办的阴谋……)
这样看上去就舒心多了~
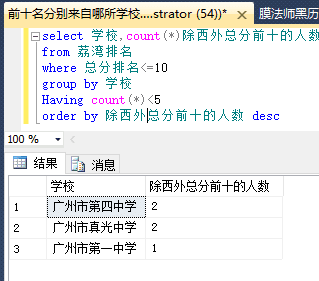
很多朋友应该都存在偏科的现象,但在我们的深入研究下,发现事情并不简单:
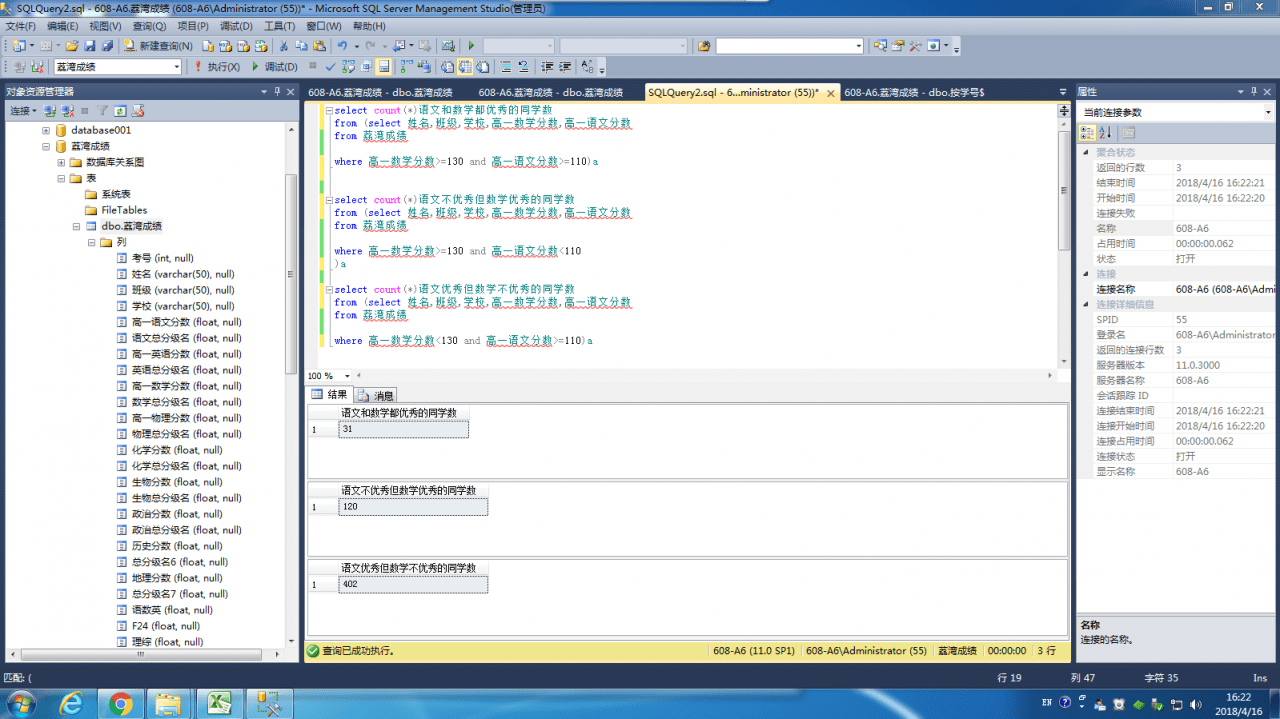
语文不好的同学不一定数学好,
但数学不好的同学就有可能语文好了……
三倍的人数差还是能说明问题的……

那么以上呢,就给大家详细展示了大多常用查询指令的用法~接下来给大家介绍的是「连接查询」,通过这个就能实现多表之间的查询了。
成绩与排名两个表连接,分析理科总成绩与数学成绩之间的关系:
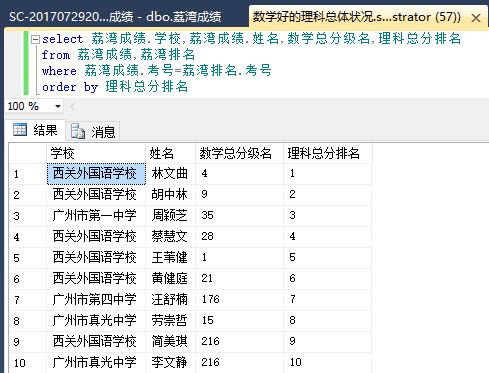
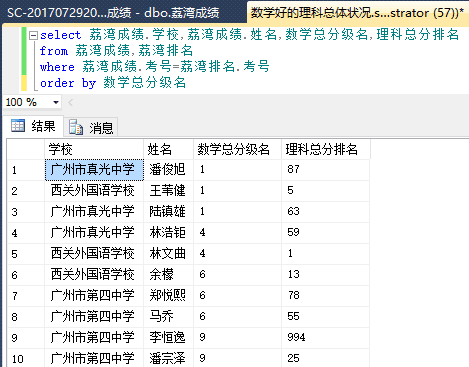
看样子综合能力好的同学,真的是每一门都不偏科呢!
最后同和君要做一件集大成的骚操作~
首先合并一下数据:
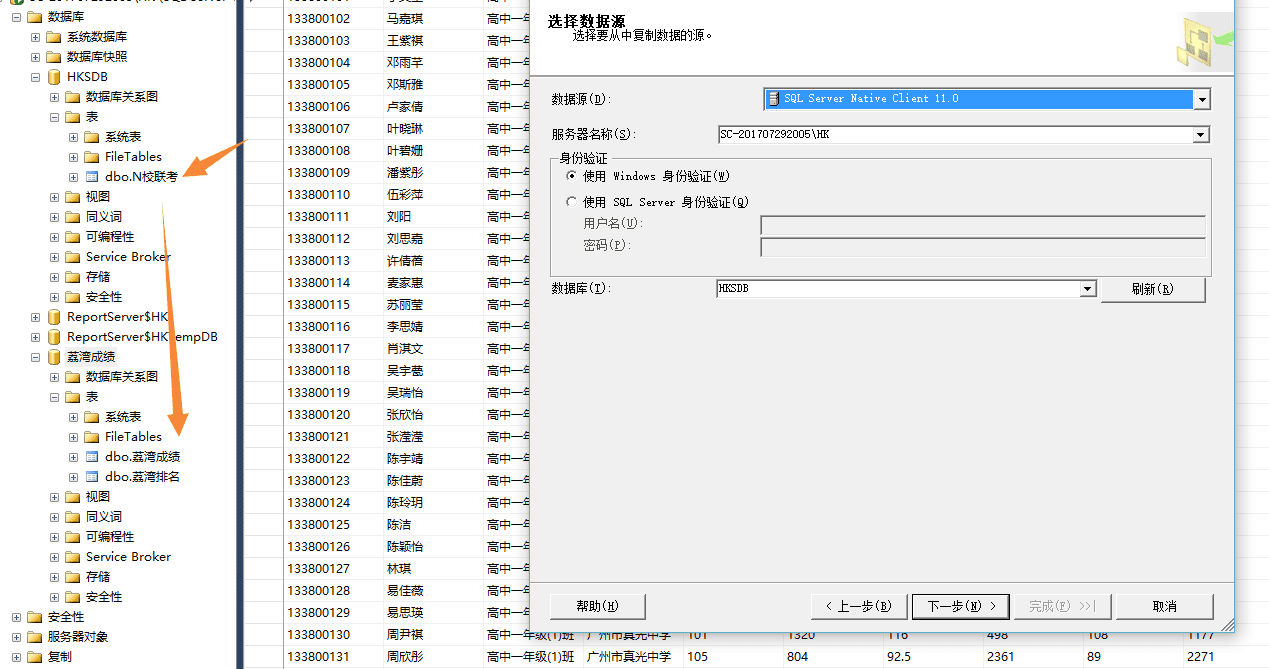
嘿嘿嘿~
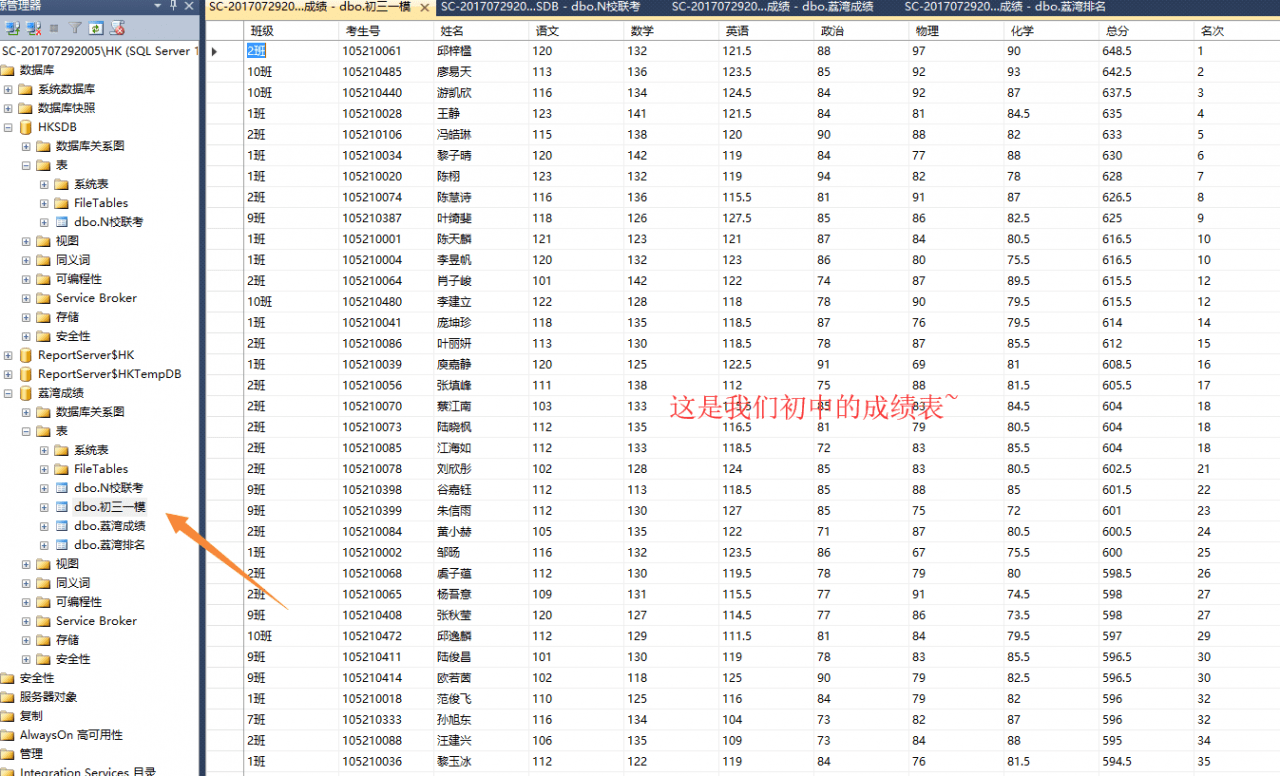
我们来看看初中的那些朋友们到了高中后学习状态如何~
唯一能对应上的只有姓名了,结果如下:
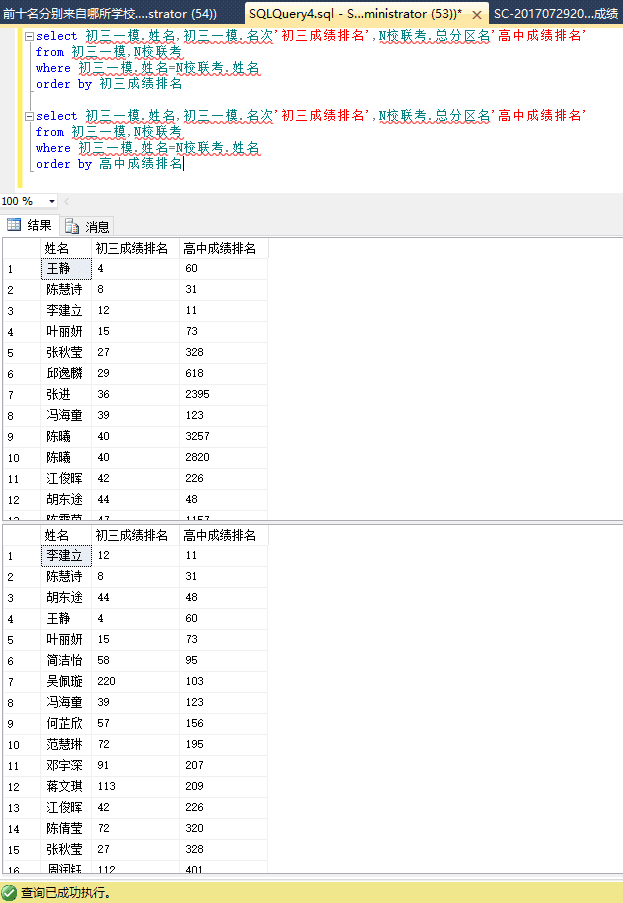
换个表试试:
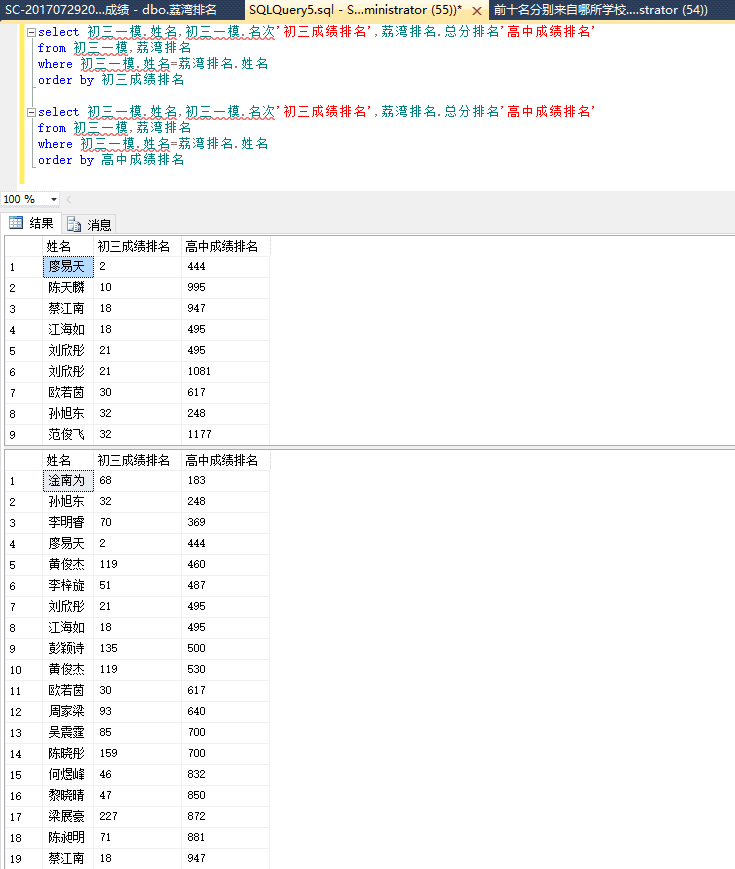
大数据显示,初中成绩好的高中成绩不一定好,但高中成绩好的初中成绩一定不差!
什么?有人想看我的成绩?
抱歉,这两个表里都没有我的名字hhh,成绩好就是可以为所欲srgsrgz
[数据删除]
大家也看到了,现在在某二本混日子的我……(;д;)
所以学习这玩意嘛……哎,不谈了不谈了……
接下来介绍一些增删查改的相关操作:
--增加一条记录
insert N校联考 (考号,姓名,班级,学校)
values('10001','同和君','一班','社会大学')
--求表中各校总分的平均分,并存入一个新的数据库
create table AvgMarks
(学校 nvarchar(255),
平均分 real)
insert
into AvgMarks(学校,平均分)
select 学校,AVG([9科总分分数])
from N校联考
group by 学校
--将「N校联考」中所有「广州市第五中学」的信息更新为「广州五中」
update N校联考
set 学校='广州五中'
where 学校='广州市第五中学'执行结果:
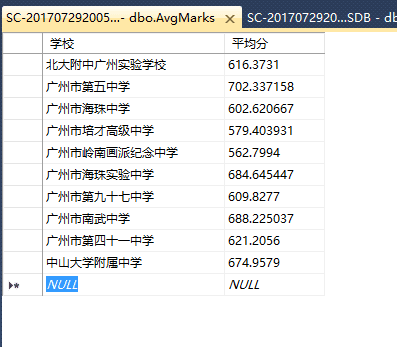
ok,那么就暂且先告一段落吧,基本操作讲完了,下回咱们就讲讲高级操作吧~

鸣谢以上十七所高校提供的成绩信息~
https://www.bilibili.com/read/cv476187SQL, 数据库, 大数据