





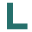





https://hocassian.cn/wp-content/uploads/2020/05/c8aa2338ab25f9a1db20a6e8e802e4dcbcf464f8.jpg
文:同和君

这件事起源于某天傍晚,大家都知道同和君是个很爱讲故事的人,当时呢也是想分享一个发生在高中时期特别搞(jin)笑(bao)的事情给朋友听,可惜其中有一个很重要的地方我记不太清楚了,只记得那件事我以前和别人也聊过,还截了图存到硬盘里。没那个情节的话整个故事也会变得索然无味……只好先拒绝了朋友(其实是想偷懒直接发截图给她看),等找到了那张图恢复了记忆再来讲述。
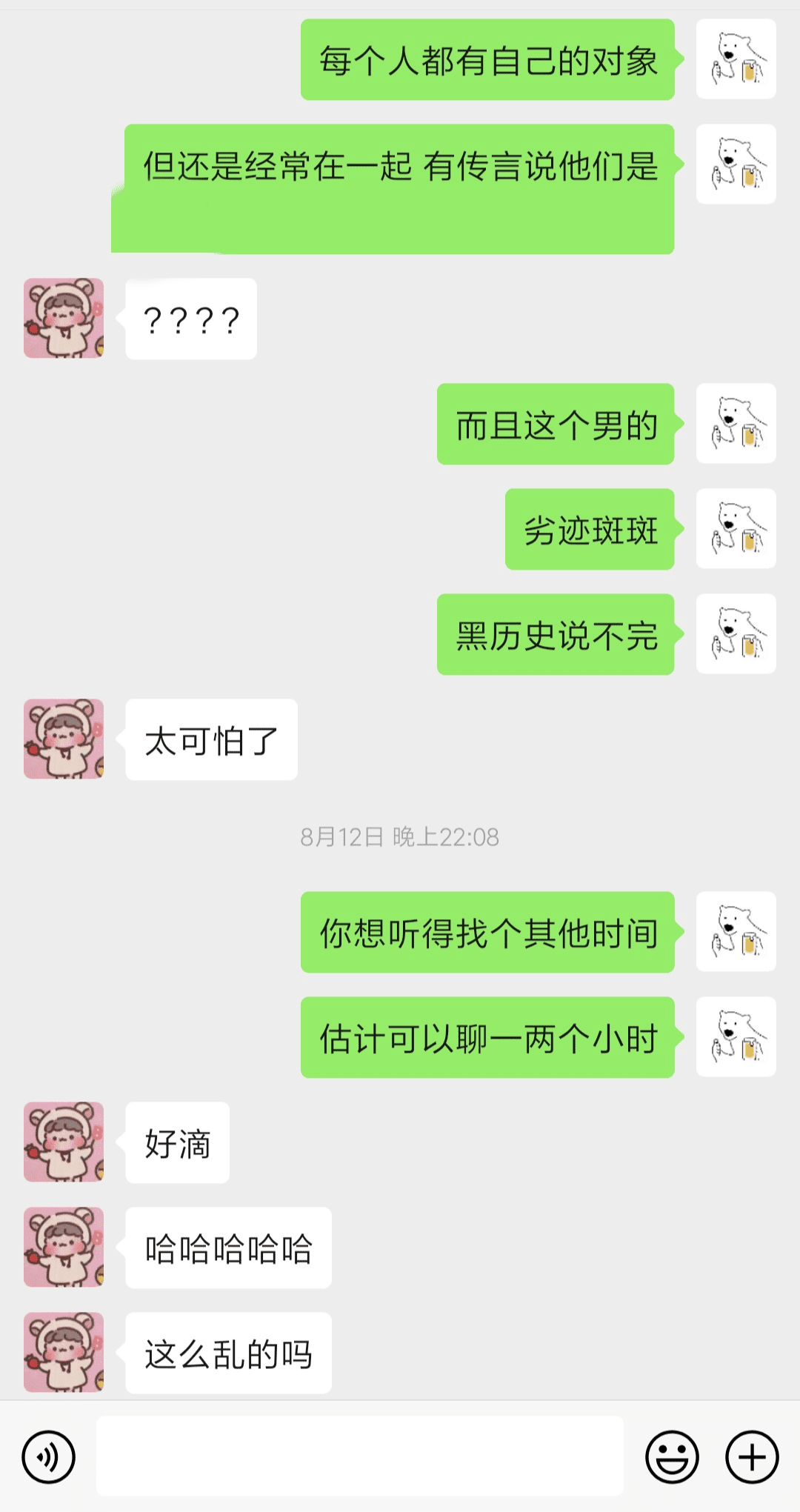
可正当我打算开始找那张截图的时候,我才反应过来,这基本上等同于大海捞针:
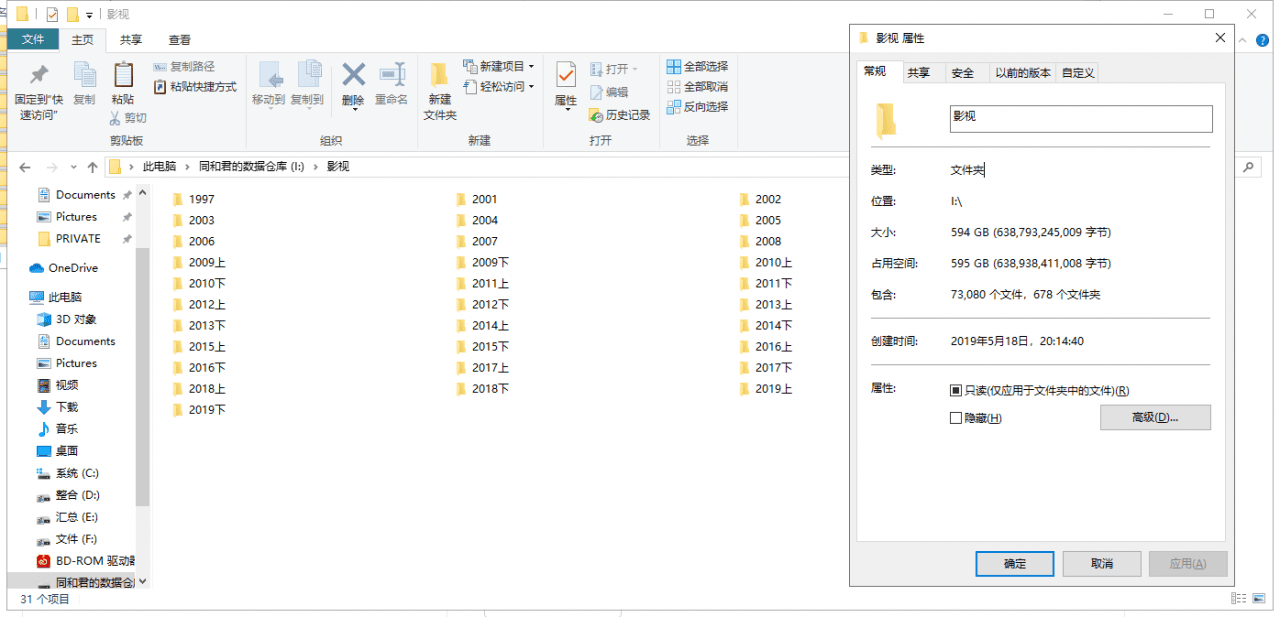
就算定位到了具体的年份,也还是有很多图片需要逐张查找……
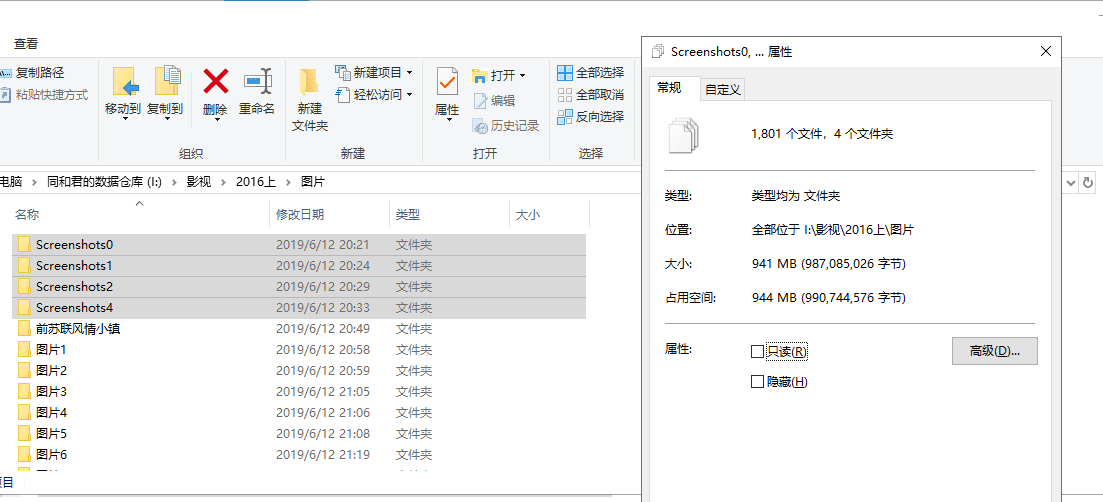
其实类似这样的事情发生过很多次,写专栏或者做视频有的时候需要用到过去的资料,还是得找上半天……

所以到底有没有什么好方法来解决这个问题呢?答案当然是有的,那就是:
只有机器才能对抗机器——艾伦·图灵

由于我之前写过一个用来自动输入校园网登陆验证码的脚本,其中自动识别验证码一项用到了谷歌的OCR工具「tesseract」(详细安装与使用教程见:https://blog.csdn.net/showgea/article/details/82656515,注意安装后重启计算机),所以我想到了要是能将图片识别出来的字段存入该图片的数据结构中,然后通过某种手段来检索,就会大大提高工作的效率了。
深入了解我发现无论是jpg还是png,常用的这些图片格式里,都存在一种叫Exif的数据结构,它用来存储照片的相关信息(元数据),比如拍摄日期、修改日期、拍摄经纬度、ISO、相机品牌等等。而这其中有一个叫「ImageDescription」的字段,即「图片描述」:
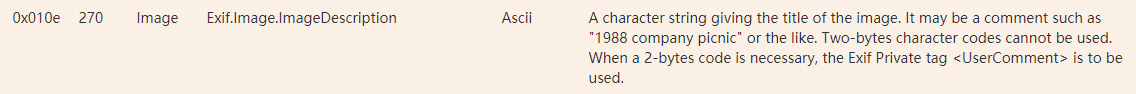
我查了很多资料都没查出来这个字段的上限究竟是多少,不过经极限测试,可以成功写入2万汉字,也就是说ocr识别出的汉字少于2w都可以写入,暂时不必担心数据溢出。
重头戏来了,如何把数据批量识别并写入呢?用Python写一个简单的脚本即可:
import os,re,time,pyexiv2
from PIL import Image
import pytesseract
class exif():
def imgSave(self,dirname):
for filename in os.listdir(dirname):
path = dirname + filename
if os.path.isdir(path):
path += '/'
self.imgSave(path)
else:
self.imgExif(path)
def imgExif(self,path):
try:
text = pytesseract.image_to_string(Image.open(path), lang='chi_sim')
string = re.sub("[s+.!/_,$%^*(+"')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+","",text)
print(string)
img_tag = pyexiv2.Image(path)
img_tag.modify_exif({"Exif.Image.ImageDescription":string})
#img_tag.modify_iptc({"Iptc.Application2.Caption":string})
print('图片'+path+'写入成功')
except:
print('图片'+path+'写入失败')
def start(self):
_path = input("请输入图片路径:").strip()
self.imgSave(_path+'\')
Exif_info = exif()
Exif_info.start()
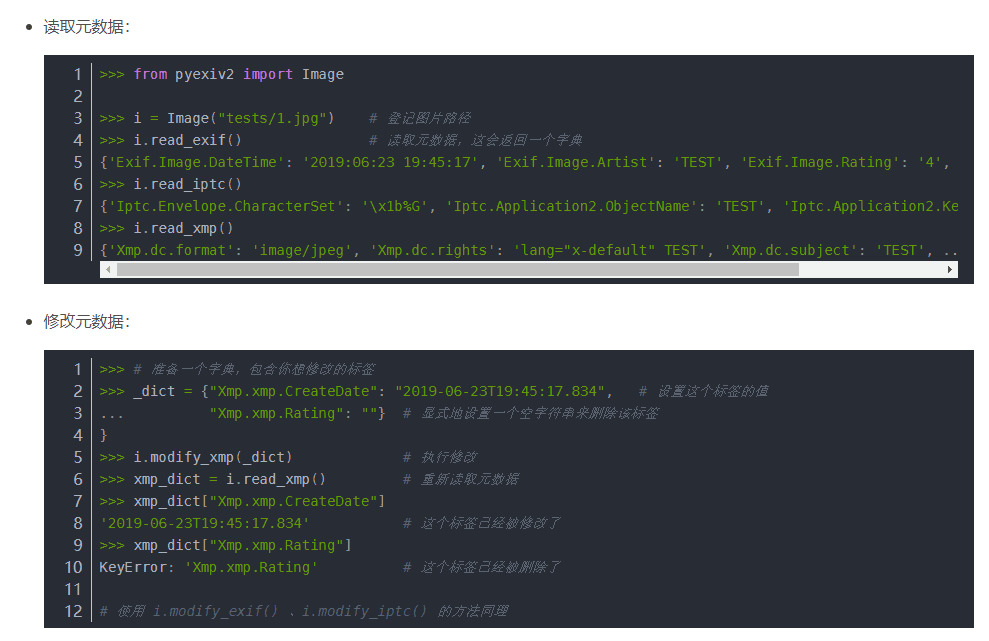
其中,有一个很重要的模块「pyexiv2」被引入,它是一个基于Exiv2的Python库,可以读写图片的元数据,用法如下:
接着整合OCR和修改元数据两个功能,再通过imgSave模块批处理,就能对数据库中所有文件进行批量修改了。
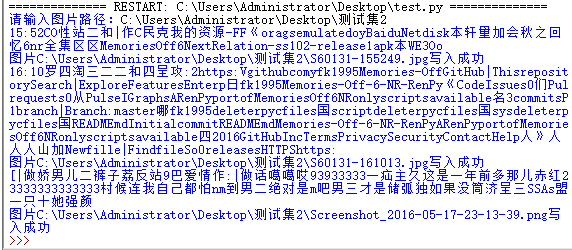
修改完后,具体如何查找呢?因为有现成的工具「Adobe Bridge」,所以就不用再另写查找脚本了,处理完后直接搜索即可:
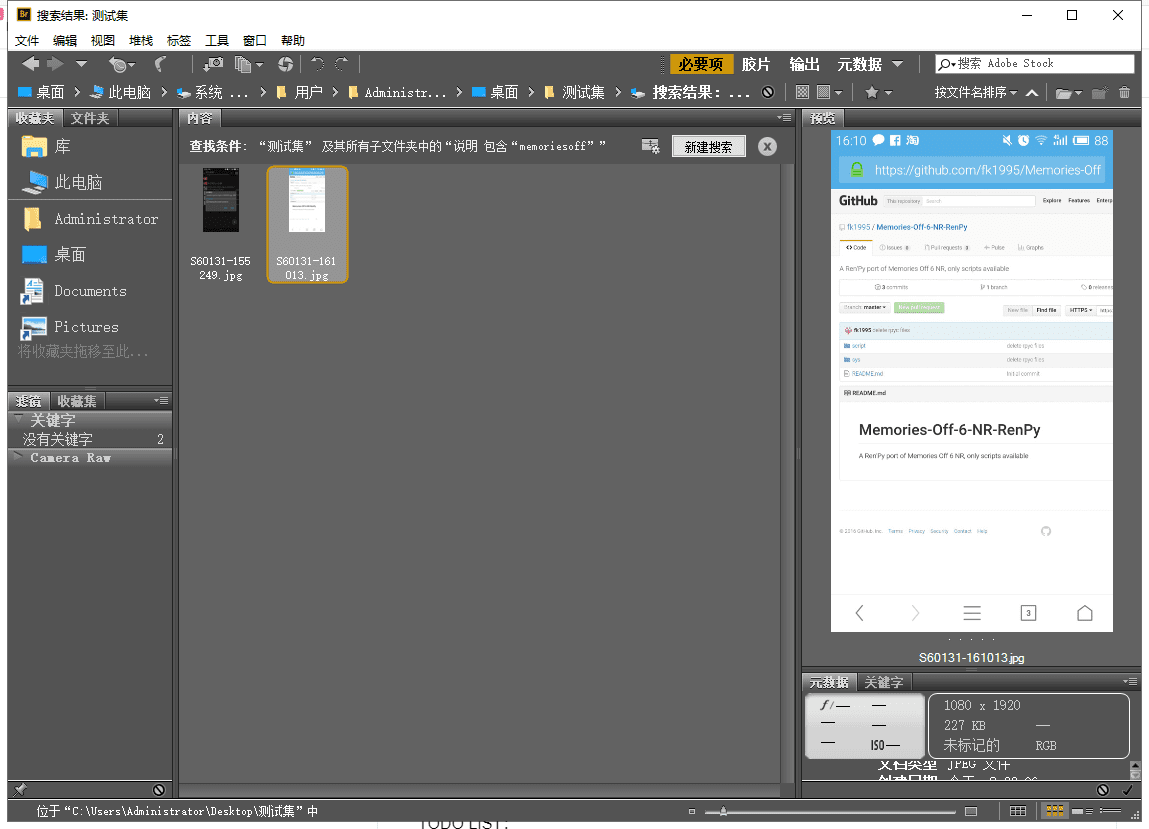
测试完成后再部署到我整个影像资料库里:

OK,现在来找找我们所需要的数据吧~
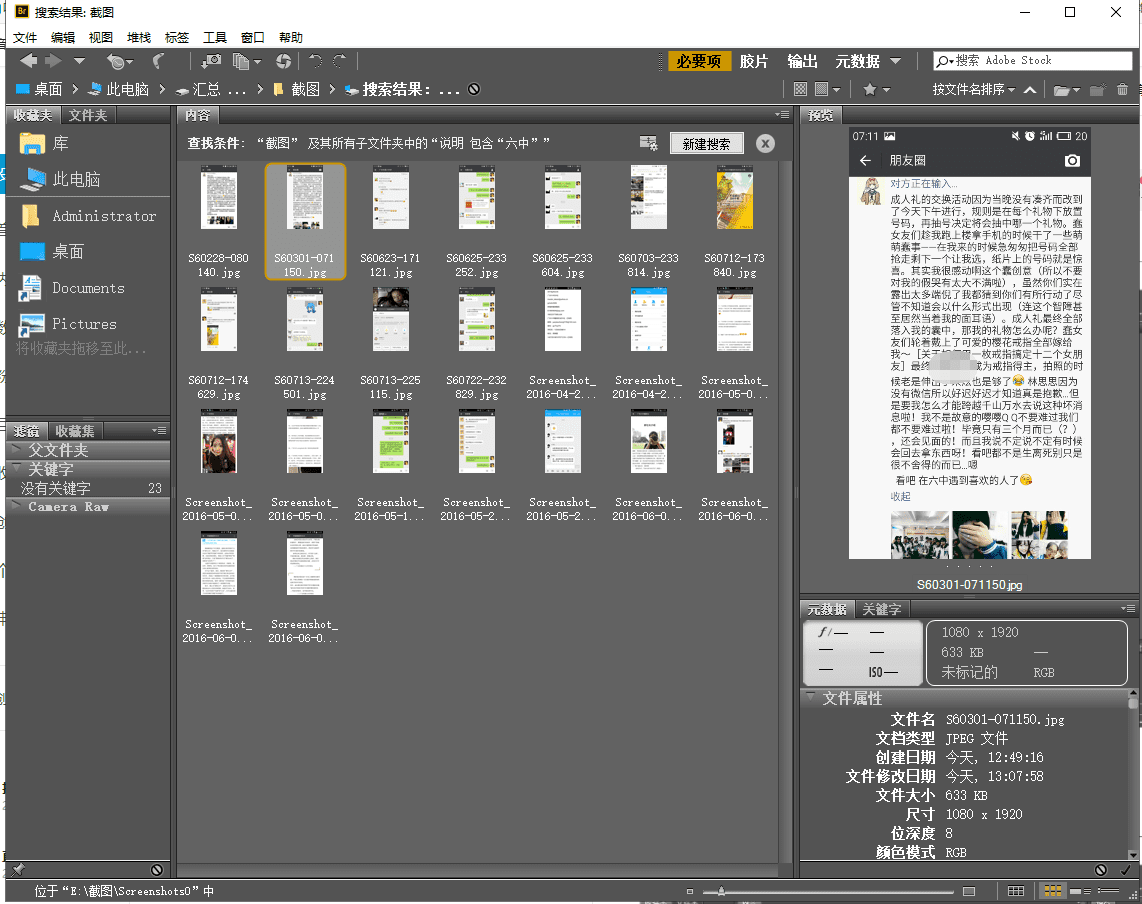
好了,继续和朋友开开心心地吹水吧~

很遗憾,因为审核问题关键图片没法放上来给大家看……
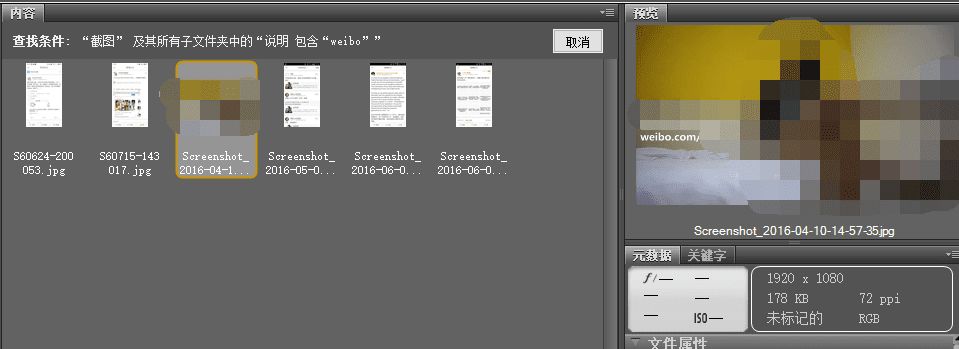
虽然解决了目前的需求,不过还是存在一些问题:
-
谷歌识别的准确率大约为80%左右,精度还需要提高;
-
因为精度不高,所以还需要加入模糊搜索功能,这就需要自己编写搜索工具了;
-
部分png不支持exif,即使写入了数据,bridge里也检测不到(但数据确实已经写入,用pyexiv2能查到写入的字段);
-
单线程OCR效率太低,可以多上几个线程。
TODO LIST:
-
写一个支持模糊搜索的图片搜索引擎

https://www.bilibili.com/read/cv3430710教程, 脚本, 编程, 分享, 搜索, 检索, Python, ocr