B站-智能成片性能优化探索与实践
发布于 2023-10-31
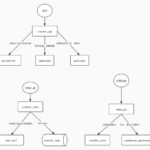
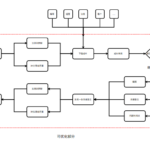
本期作者 徐惠雨 哔哩哔哩资深开发工程师 一. 前言 各类剪辑类工具中都有一键成片的能力,解决创作者在视频创作中剪辑特效包装难的问 …

這個宇宙,因深愛著你而閃耀光輝。









同和君の老本行。
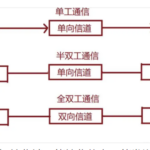
无论是游戏场景还是密集运算场景,双工通信已经算是一个老相识了;我们这次仅仅用ws举例,说明不同的连接之间如果想传输信息、交互,该如 …
输入ffmpeg/ffprobe后回车,有这样的输出说明安装成功。 Win 本地下载地址:https://ops.hocassia …
今天开发中遇到了一个很有意思的事情,就是我想在两段长音频中合并一段长度为300ms的静音片段作为分隔,然后用ffmpeg也好,用l …
验证了我之前的猜想,假如开发的软件纯调用ffmpeg的话,可以不开源、可以收费 GPT4问答 What’s the differe ̷
最近要训练某个漫画图片/动漫视频填字的模型,需要大量的漫画素材,于是直接就想到E绅士网站肯定有最全面的资料XD~ 刚好朋友有比较资 …
使用python相关库from elasticsearch import Elasticsearch创建: self.es_cli …
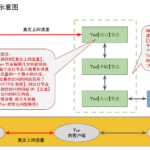
麒麟安全网络锦标赛:国内匿名网络先导配置 本教程以ubuntu 20.04系统为例,设置Tor+ssr前置代理的匿名网络服务,方便 …

以下方法都是我当年大学时琢磨出来的,基本不需要什么前期投入和学习成本,但是需要适当放低一点自己的人品和底线,没办法啊,原始积累都是 …