










同和君の开发手册
近日 todo list:
开发创作矩阵人脉网前端
开发智能服务柜
开发素材矩阵客户前端
开发分发矩阵后端
虾米音乐入库(这项目搞了快半年了)(进度99%)
个人双周报
运营指南&商业化:同和系驻头条:商业调查报告
各项资源部署:项目资源索引
私有化部署:同和新媒体矩阵·项目支持会
最近の学习:Neo4j 学习手册
更多可公开的技术就不写外部文档了,可以去这里看看~欢迎关注我的头条、b站、Github~
各等级标题简介:H1为项目名称,H2为技术问题&沟通问题的总结,H3为各类总结的子项目。
一、Jira工单通知卡片
1、技术总结
1.1、为何服务端用「rfile.read()」接收客户端发来的响应主体?
最近做项目读源码的时候发现了一个有趣的方法,国内开发论坛基本没有人提起过,大佬们在Python中通过这种方法接收客户端发来的响应主体:
# 解析请求 body
req_body = self.rfile.read(int(self.headers['content-length']))
obj = json.loads(req_body.decode("utf-8"))
print(req_body)

由于这段代码在公开的demo里所以直接放出来给大家看了,首先是把content-length字段转为int,然后直接送去给rfile.read()使用……这就很奇怪了,读一个数字能读出什么具体信息来呢?相当于一个聚会上有张三李四王五等很多人,我只告诉你人数,让你把他们的名字复述出来,这怎么可能呢?
还是从方法本身出发,我们看官网对rfile的介绍:

然后不要漏掉看使用了这个方法的父类:

BaseHTTPRequestHandler下各种子类就是用来响应客户端请求的各类方法,而rfile相当于是已经包含响应全文了,传入的int提示read()方法应该分配多少内存空间用于读取,类似于java里的哈希表。因为在传输过程中,只有header的数据类型和大小是确定了的,而其他的都没有。不像本地文件那样已知文件大小可以直接open(),这种流文件在未知大小的情况下,系统在得知具体文件大小之前是无法随意分配空间的。需要注意的是,rfile是io.BufferedIOBase的派生类,BaseHTTPRequestHandler只是使用了它而已,他们有点类似java里Object、Lang、IO等基础类的关系。
需要注意的是,这样提取的数据还是二进制的,需要通过decode解码为相应数据类型。额外多说几句,python里还有rfind方法,是用来寻找最后一个出现的特征值的,而这个rfile其实也有类似的意思,即读取到报文的最后一个数据。有些网站在加载后台资源的时候,为了加速前端的回调,会直接在索引文件中给出该资源的大小长度:
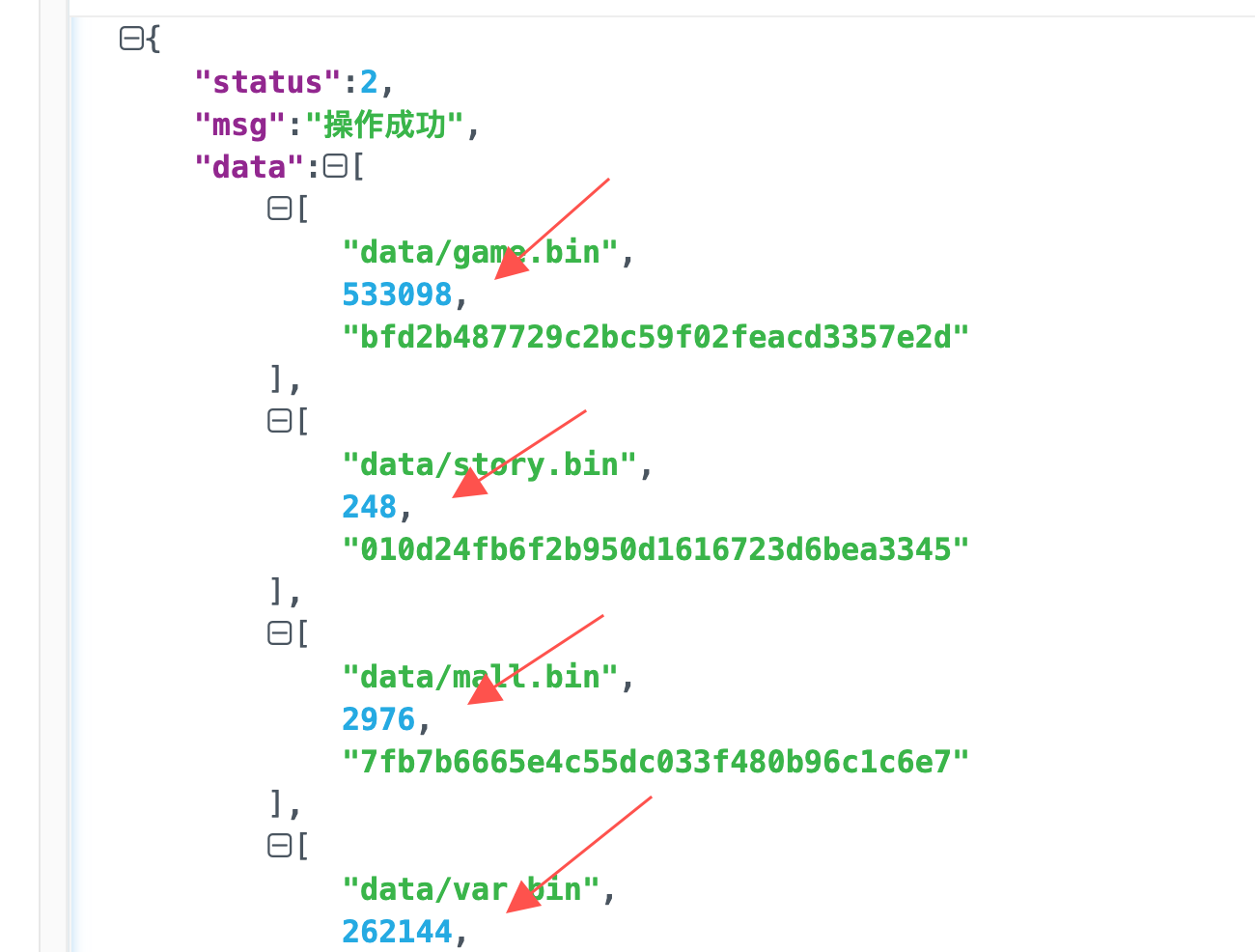
1.2、飞书机器人后端逻辑
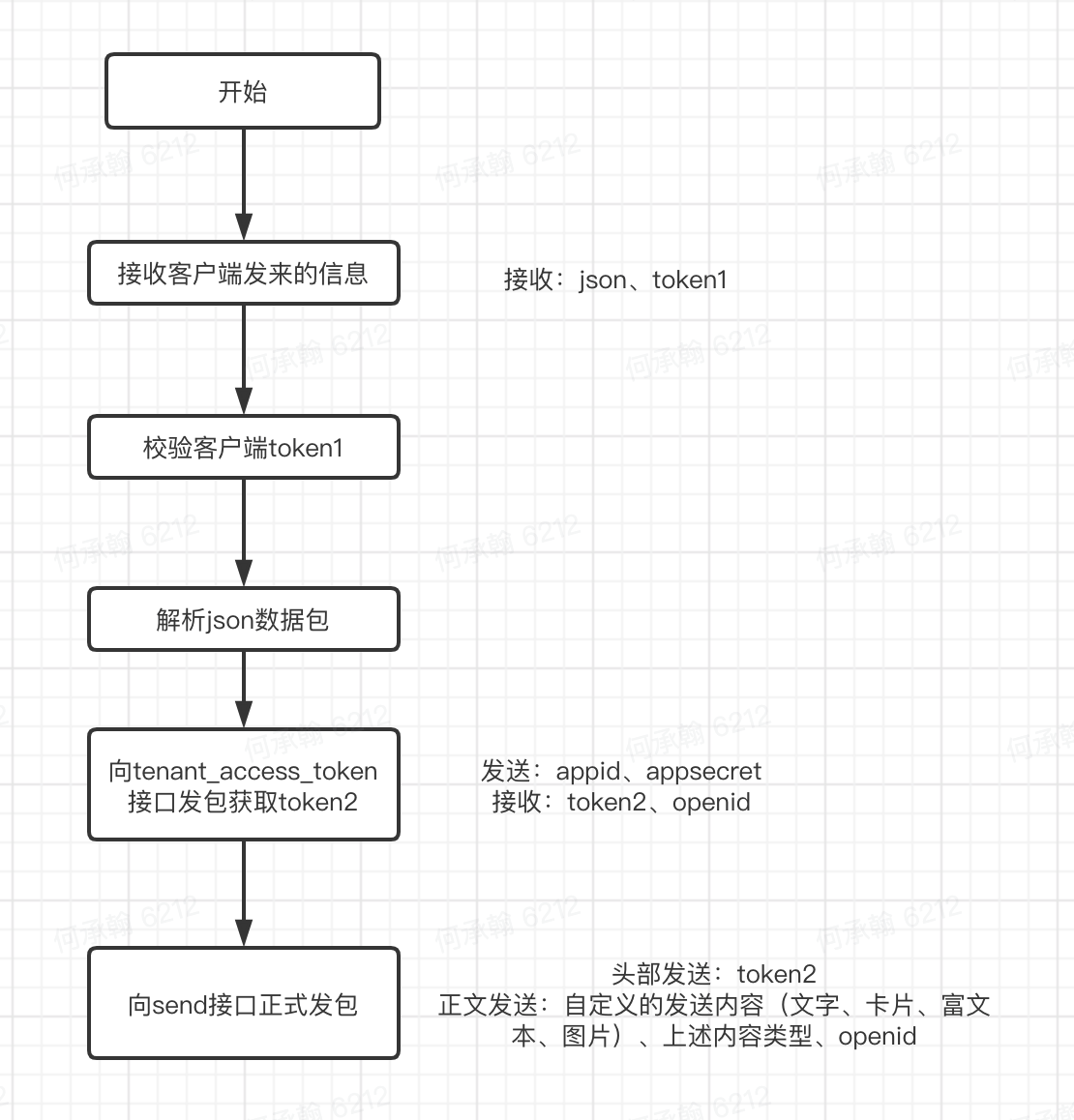
用户发来的信息:
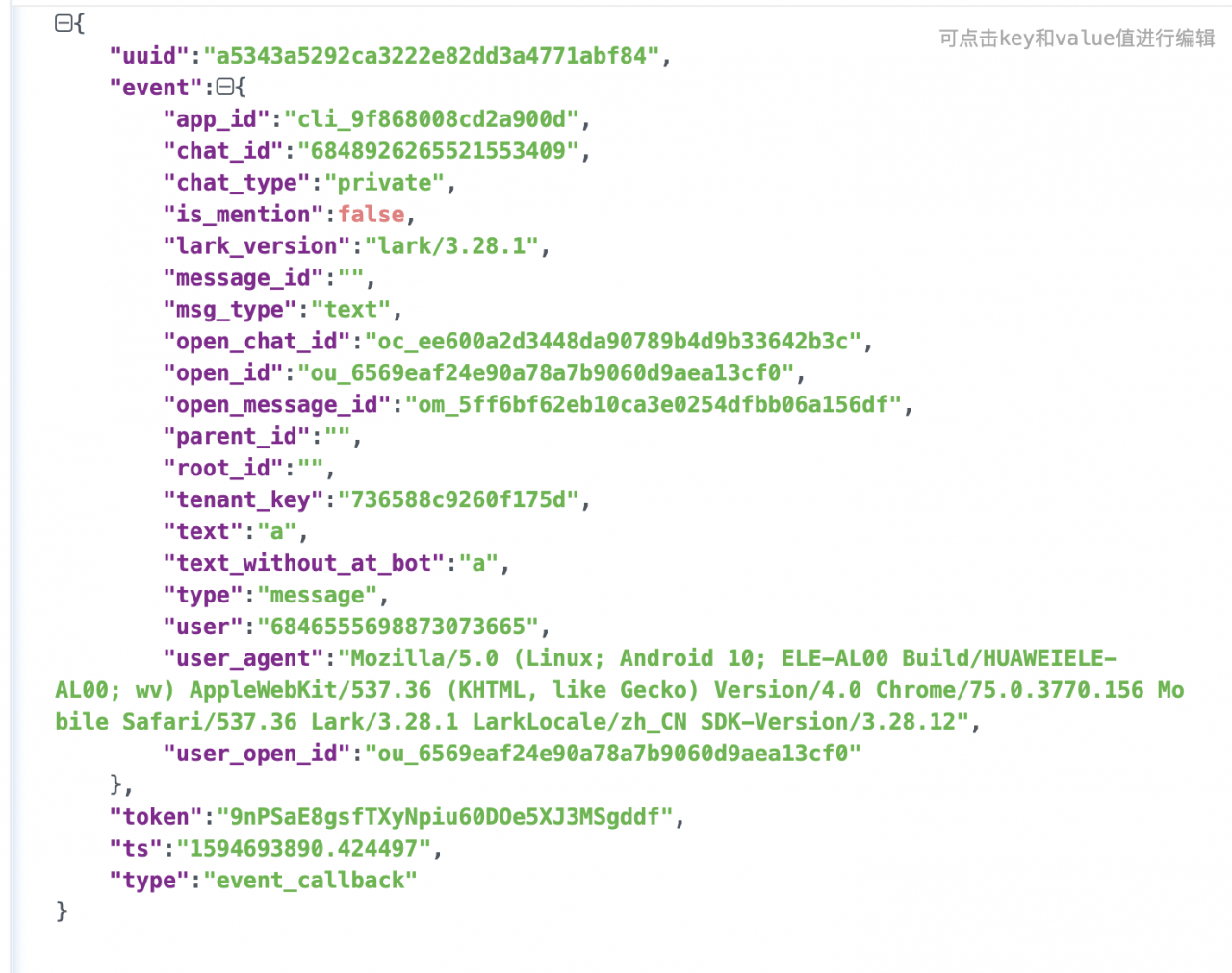
脚本通过app = Flask(__name__)确定运行主体,然后通过@app.route('/', methods=['POST'])注册路由,最后如下运行Flask任务:
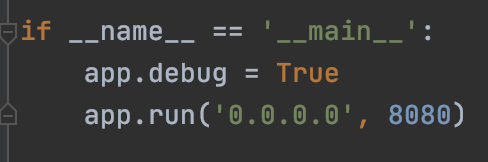
APP_ID、APP_SECRET、APP_VERIFICATION_TOKEN三个参数,用在应用详情中获取到的值来进行正确的赋值。
do_POST 函数,解析由开放平台推送过来的http请求包,并根据不同的事件类型来进行相应的处理。
handle_request_url_verify 函数,主要在保存请求网址url时进行校验。
handle_message 函数,处理开放平台推送过来的事件
get_tenant_access_token 函数,机器人在向用户发送消息时,获取tenant_access_token
send_message 函数,机器人发送消息
示例代码:https://sf1-ttcdn-tos.pstatp.com/obj/website-img/093b18e5189ad423a378b616b1bf94c3_Tbosxo7mus.py
#!/usr/bin/env python
# --coding:utf-8--
from http.server import BaseHTTPRequestHandler, HTTPServer
from os import path
import json
from urllib import request, parse
APP_ID = "cli_XXXX"
APP_SECRET = "XXXX"
APP_VERIFICATION_TOKEN = "XXXX"
class RequestHandler(BaseHTTPRequestHandler):
def do_POST(self):
# 解析请求 body
req_body = self.rfile.read(int(self.headers['content-length']))
obj = json.loads(req_body.decode("utf-8"))
print(req_body)
# 校验 verification token 是否匹配,token 不匹配说明该回调并非来自开发平台
token = obj.get("token", "")
if token != APP_VERIFICATION_TOKEN:
print("verification token not match, token =", token)
self.response("")
return
# 根据 type 处理不同类型事件
type = obj.get("type", "")
if "url_verification" == type: # 验证请求 URL 是否有效
self.handle_request_url_verify(obj)
elif "event_callback" == type: # 事件回调
# 获取事件内容和类型,并进行相应处理,此处只关注给机器人推送的消息事件
event = obj.get("event")
if event.get("type", "") == "message":
self.handle_message(event)
return
return
def handle_request_url_verify(self, post_obj):
# 原样返回 challenge 字段内容
challenge = post_obj.get("challenge", "")
rsp = {'challenge': challenge}
self.response(json.dumps(rsp))
return
def handle_message(self, event):
# 此处只处理 text 类型消息,其他类型消息忽略
msg_type = event.get("msg_type", "")
if msg_type != "text":
print("unknown msg_type =", msg_type)
self.response("")
return
# 调用发消息 API 之前,先要获取 API 调用凭证:tenant_access_token
access_token = self.get_tenant_access_token()
if access_token == "":
self.response("")
return
# 机器人 echo 收到的消息
self.send_message(access_token, event.get("open_id"), event.get("text"))
self.response("")
return
def response(self, body):
self.send_response(200)
self.send_header('Content-Type', 'application/json')
self.end_headers()
self.wfile.write(body.encode())
def get_tenant_access_token(self):
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal/"
headers = {
"Content-Type" : "application/json"
}
req_body = {
"app_id": APP_ID,
"app_secret": APP_SECRET
}
data = bytes(json.dumps(req_body), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
try:
response = request.urlopen(req)
except Exception as e:
print(e.read().decode())
return ""
rsp_body = response.read().decode('utf-8')
rsp_dict = json.loads(rsp_body)
code = rsp_dict.get("code", -1)
if code != 0:
print("get tenant_access_token error, code =", code)
return ""
return rsp_dict.get("tenant_access_token", "")
def send_message(self, token, open_id, text):
url = "https://open.feishu.cn/open-apis/message/v4/send/"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + token
}
req_body = {
"open_id": open_id,
"msg_type": "text",
"content": {
"text": text
}
}
data = bytes(json.dumps(req_body), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
try:
response = request.urlopen(req)
except Exception as e:
print(e.read().decode())
return
rsp_body = response.read().decode('utf-8')
rsp_dict = json.loads(rsp_body)
code = rsp_dict.get("code", -1)
if code != 0:
print("send message error, code = ", code, ", msg =", rsp_dict.get("msg", ""))
def run():
port = 8000
server_address = ('', port)
httpd = HTTPServer(server_address, RequestHandler)
print("start.....")
httpd.serve_forever()
if __name__ == '__main__':
run()
1.3、写一个「同和搜图」练练手
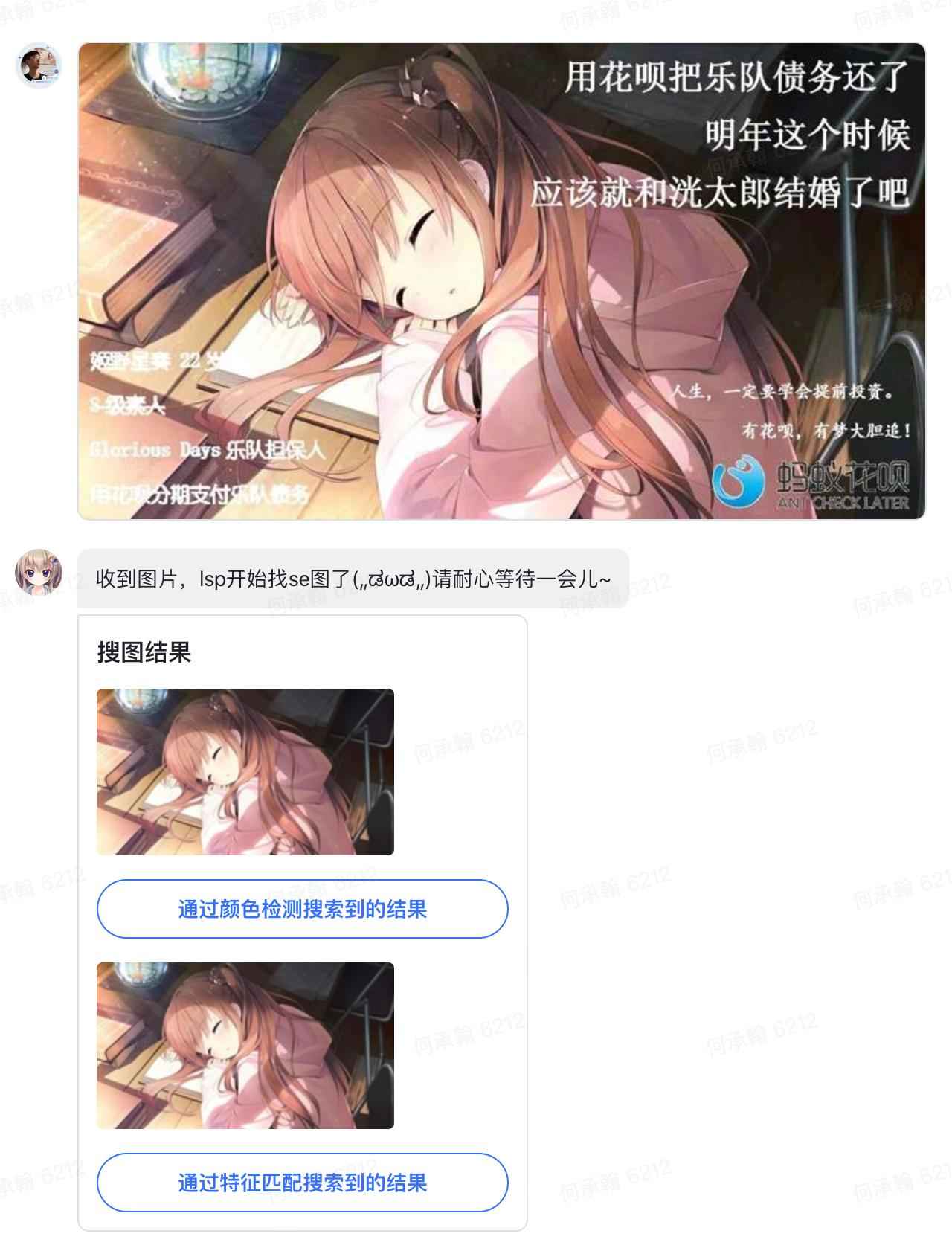
进公司前曾经和小伙伴写过一个在QQ群里部署的搜图机器人,后端服务的api来自知名搜图站「ascii2d」,前端机器人通过监听群员发言的方式被激活,然后读取图片进行搜索,接着返回结果。入职之后发现正好飞书提供了一个平台,遂移植之。
写的过程中就发现,其实很多功能都可以模块化,比如鉴权模块(获取tenant_access_token)、校验模块(绑定服务端口时原样返回 challenge 字段内容)等等,然后就遵循「高内聚,低耦合」的原则分开来设计了,需要调用时直接「函数对象化」。
这个项目的重难点在于如何与目标站点「对话」,即需要理清楚用户与服务器之间的逻辑关系:用户给飞书机器人发送图片→后端接收到img_key→通过key从飞书服务器获取图片→把这个图片上载至「ascii2d」api接口→等待并解析返回值,获取目标网址和图片缩略图→将图片上载至飞书服务器→返回给用户img_key→飞书前端解析最终结果。这一过程需要多次使用request或requests进行web请求,和类似爬虫的方法从获取的网页中解析需要的信息。
最终效果:
不足之处&待改进的地方:
增加机器人的互动性,例如发图前提示「请发给我图片」和发图后「请耐心等待1分钟」
由于内网的特殊性就不搬过来了,目前该机器人后端使用的是个人国内的腾讯云服务器,这也导致执行完整个流程需要非常长的时间(「ascii2d」网站在日本,且搜图服务器本身也需要时间来返回结果),所以需要增加几个线程来应付多人同时搜图的情况,外加异步的方法告知用户耐心等待。
1.4、面向流程编程
然后就进入正式开发的阶段了,由于需求涉及的工单数据太多太广,有些特殊的字段甚至需要回调api加参数才能获取,故后端一律设计为:Jira向后端发送如下格式的WebHook,然后后端通过回调Jira服务器api来获取更详细的数据:
{
"key": "IT-XXXXXX",
"flag": "评论/状态"
}
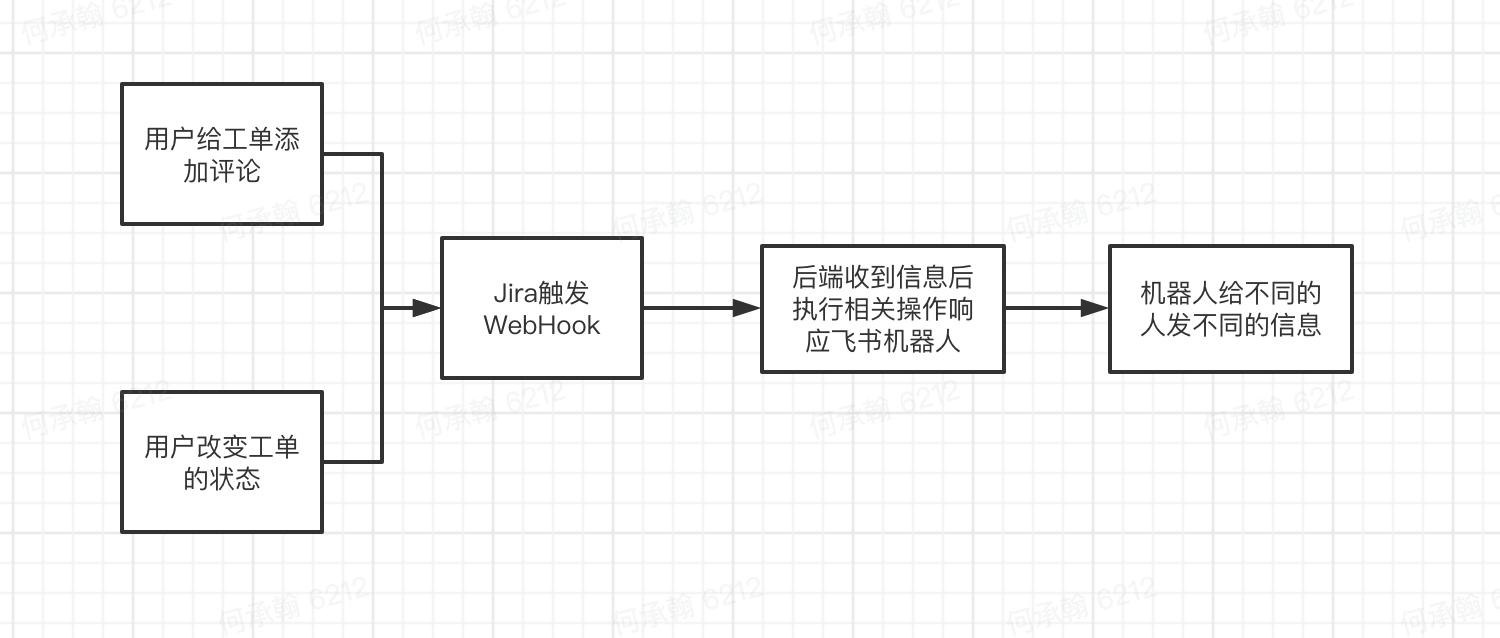
和过去公司里面向对象CRUD的项目不同的是,面向过程尤其注意不同操作下系统执行的逻辑。在多个if-else的嵌套下,逻辑很容易就开始离散了:A操作会不会被B操作影响?为了防止这种影响需要添加&改变怎样的触发条件&特征值?有些情况很难通过常规的思路去想到,比如工单取消&解决后的评论如何处理?工单如果改变指派人呢?不同种类的工单有不同的状态该如何分别应对?类似的问题产生的Bug有很多,大部分都是通过实际的测试才发现的,这和我过去的项目经历有天壤之别。
以下贴出一些典型的问题&解决方案:
1.5、算法相关
1.5.1、处理映射表

这里有很多状态需要映射,相当于组建好一个字典类型的数据集后,通过value(输入:工单内部状态)倒推出key(输出:工单对外状态),还要考虑中英文的情况。于是我编写了以下遍历查值模块来解决这个问题:
def status_transfer(statue):
ticket_dict = {
"等待支持中$Waiting for Support" : ["Waiting for support"],
"已指派处理人$Assigned" : ["Acknowledged"],
"审批中$Waiting For Approval" : ["Waiting for Approval", "审批中"],
"采购中$Waiting for Procurement" : ["Waiting for Procurement", "采购中"],
"处理中$In Progress" : ["处理中", "In Progress", "Escalated", "Waiting for Solution", "Communicating", "Pending"],
"已解决$Resolved" : ["Resolved", "已解决"],
"已取消$Canceled" : ["Canceled", "已取消"],
"已领取$Received" : ["In Use", "已领取"],
"已准备好,等待领取$Asset Ready, waiting to be picked up" : ["In Preparation"],
"已关闭$Closed" : ["Closed","已关闭"]
}
for i in range(len(ticket_dict)):
if statue in list(ticket_dict.values())[i]:
return list(ticket_dict.keys())[i].split("$")
return [statue,statue]
1.5.2、通过参与者历史信息筛选新发送对象
需求里有一项比较特别的,那就是添加参与者后仅发送给新增的参与者,而每次变更有可能添加一个,多个,甚至删除成员……所以筛选新对象就是个比较有意思的操作了。

1.5.3、当操作人在通知者列表中时,不推送通知给ta
通过以下逻辑在最后发出的列表中执行检索即可:

1.6、建立markdown卡片需要留意的地方
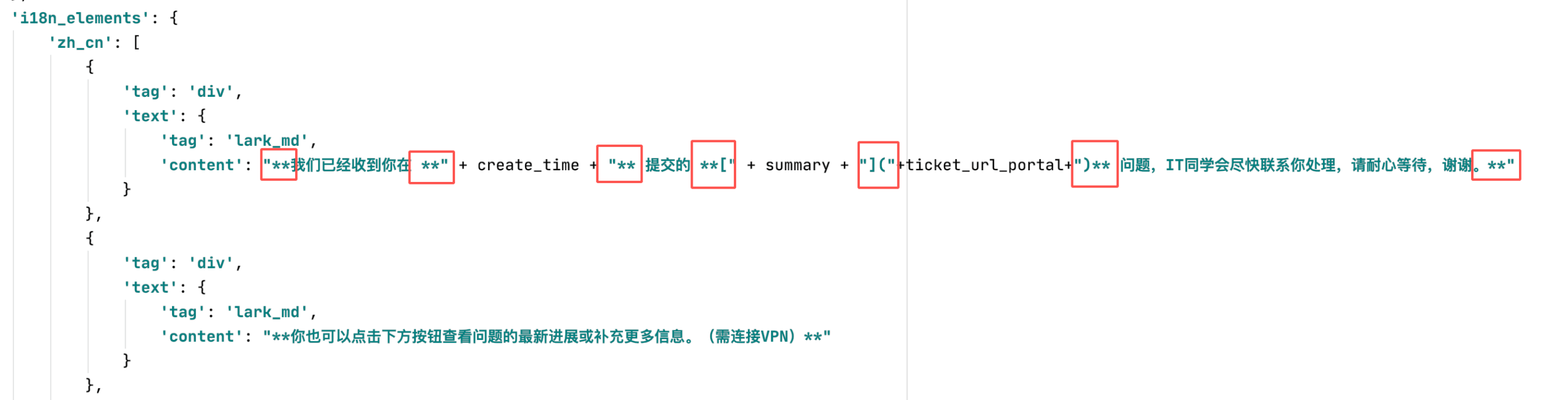
由于返回json包含markdown文本格式,由**、[]、()、空格等元素组成,拼接的时候稍不留意极容易出错,特别在此注明:
2、沟通总结
2.1、如何向PM和需求方解释特别复杂的逻辑
由于上述复杂流程中各类奇奇怪怪的bug时常会出现,而导致那些问题背后的逻辑又十分复杂,部分逻辑的漏洞甚至会倒推出需求设计的不合理,这就需要和需求方解释清楚了。很多时候我们开发人员能够理解这种缺陷,但需求方没听懂,也不知道该如何修改;这种情况下,我们得学会找合适的人解释合适的事情,首先和PM解释清楚,当代码逻辑过于复杂,如果PM也难以理解,就需要用ta能理解的领域和语言来解释,毕竟工程师注重代码逻辑本身,而产品经理注重用户的体验与需求。在解释的过程中需要举出实际的例子,模拟用户场景可能出现的问题,把大逻辑拆分为小逻辑逐层推进,放慢语速,在关键点时询问对方能否理解;待内部沟通完毕后,再由PM向需求方反馈,这样大家都能各司其职,效率也会提升。
2.2、学会求助
当项目遇到瓶颈时学会向前辈们求助,主动联系大佬并逐行解释自己的代码和逻辑,从而检查出自己的设计漏洞和实现漏洞(有没有更好、更高效的方法?)。
2.3、明确需求
看完需求文档之后自行列出具体需要完成的需求点,并且做好归类,哪些需求可以共用,哪些需要分什么样的模块,必要时主动联系PM复述一次需求,这样能够最大化地避免理解错误,从而避免徒劳的闷头开发。
2.4、开发习惯
来到大厂做开发,流程会比小型公司严谨与复杂的多,有些看似繁琐费时的工作,比如编写需求文档、测试文档、项目总结文档等,实际上反而节省了沟通与开发的时间成本,他们通过明确需求和梳理逻辑,让整个开发流程变得清晰有条理;尤其是测试这方面在过去的开发中并没有养成很好的习惯,通常是不怎么测试直接发布,用户遇到bug了再修理,「现用现修」的方式很明显不能用于目前的工程,有时我和朋友这样开玩笑:「大家都说大厂“面试造航母,工作拧螺丝”,但实际上呢?人家一颗螺丝就顶你一艘航母了。」写出来的程序每天成百上千人在用,如此高负载的程序是绝对要保持最小的出错概率的,这也是本次开发中最大的感悟。
2.5、和技术大佬如何高效率有条理的沟通
首先描述项目背景,接着说明项目现状,然后说清楚「我要做什么」,接着让大佬提出项目的各种问题并逐条记录下,讨论完后复述一遍问题防止错漏,接着给出明确的回复时间(不一定解决,可能是给出解决的思路),最后表示「如果还有什么问题可以随时联系我补充」。
二、从Jira系统到IT工作流:如何通过设计模式优化开发
1、设计模式总结
以下举例23种国际通用设计模式和若干种「杂交」奇门异术,描述语言均使用个人曾经参与过的项目经历,不特指某种编程语言,方便个人的理解与二次运用。注意,有些模式之间很类似,甚至作用重叠,运用方式可大可小,这是由于模式并不是完全隔离和独立的,有的模式内部其实用到了其他模式的技术,但是又有自己的创新点,如果一味地认为每个模式都是独一无二,与其他模式完全区别的,这是一种误区;这也是为何本章后段提到了若干种相对个性化的设计模式——那些都是个人和朋友们在实际开发和需求中总结出的方法,它们可以解决特定需求里的特定问题,由于普适性没有前23种那么强,所以列出仅供了解。
公司项目参考:设计模式 及其 在 javascript & react 中的应用
同学开发经验:有关代码设计的一些思考
理论研究相关:《设计模式》读书记录分享-蔡智明
由于太长太多,就不挂这边了,详情见:设计模式总结
2、具体设计方案
真正上手Python面向对象编程之后才发现,从JAVA过度到Python,现在基本都是继承转依赖了,然后发现只要把握两个大前提,一个是解耦,还有就是新增功能时尽可能不修改原有代码,基本就够用,具体的设计模式嘛,学习时重意, 工作时用形;只有熟悉业务才能做出更加符合当前需求场景的设计,而不是过早的追求极致的灵活性。
项目暂定名称:工单综合处理后端,我们打算以同步需求推进的形式来不断完善这个系统,针对比较特殊(今后不会复用)的需求额外开模块执行,对于比较常规的需求就需要不断扩展系统的兼容性,以适应未来的复用。
用户配置webhook
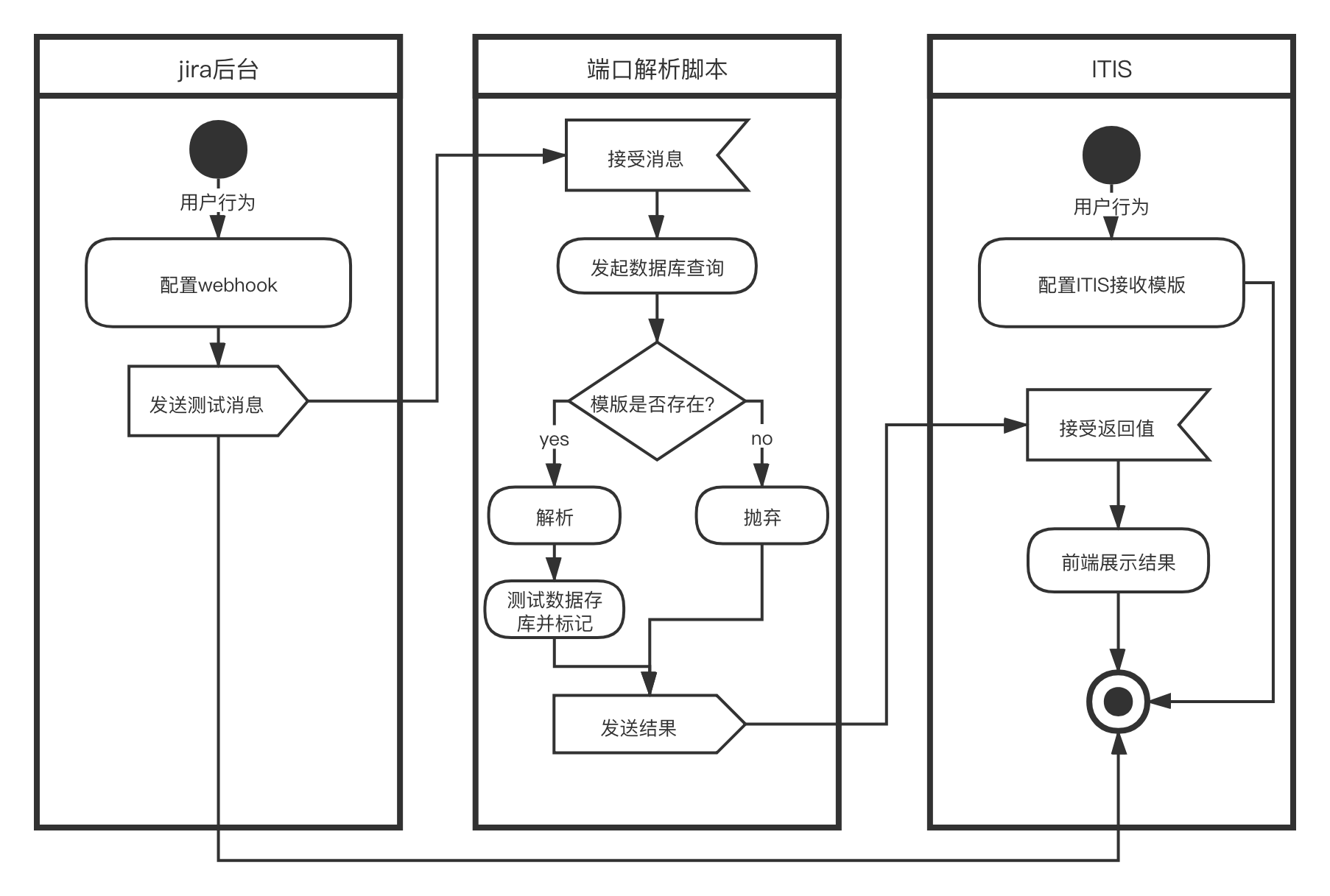
用户配置卡片
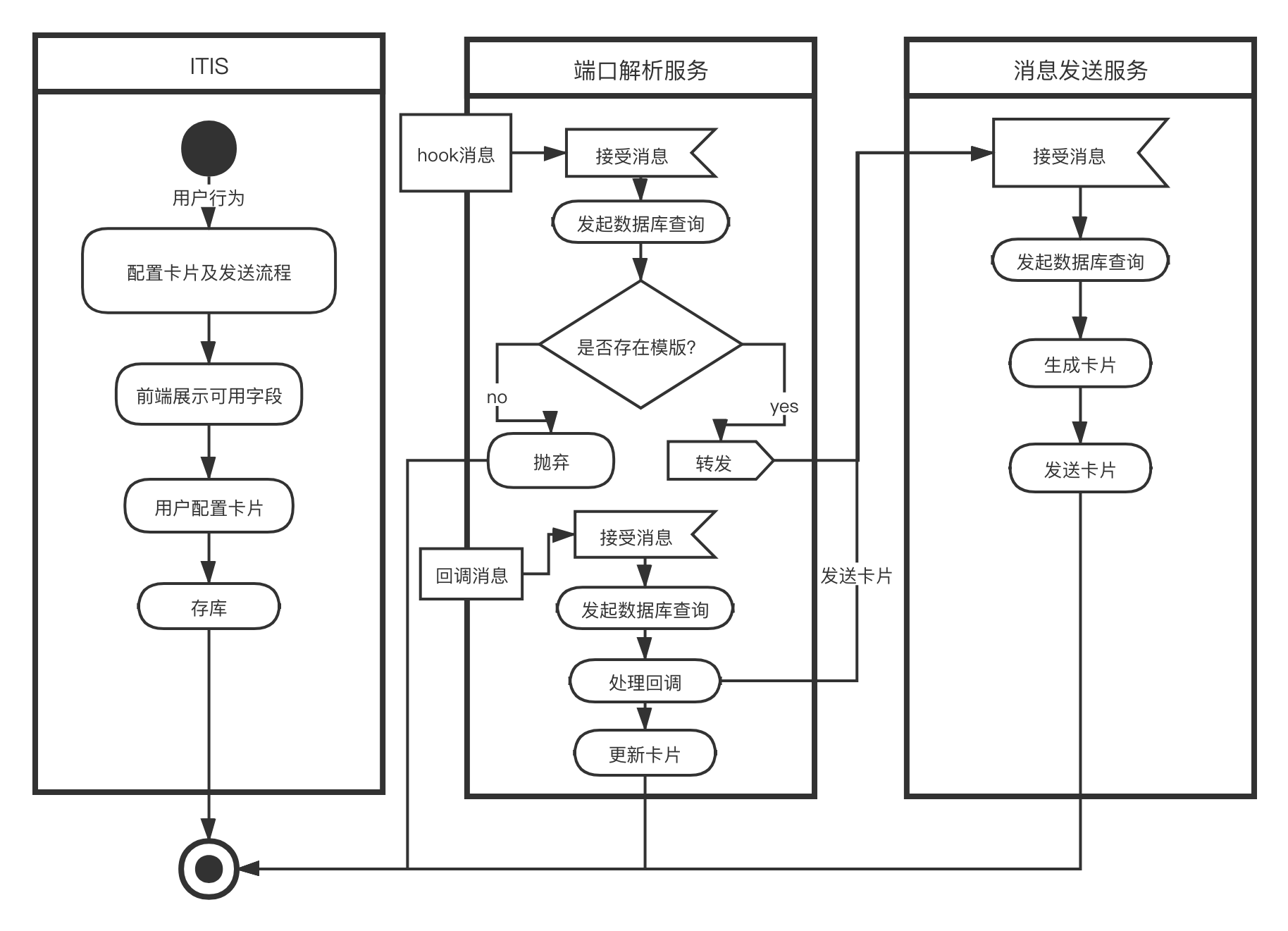
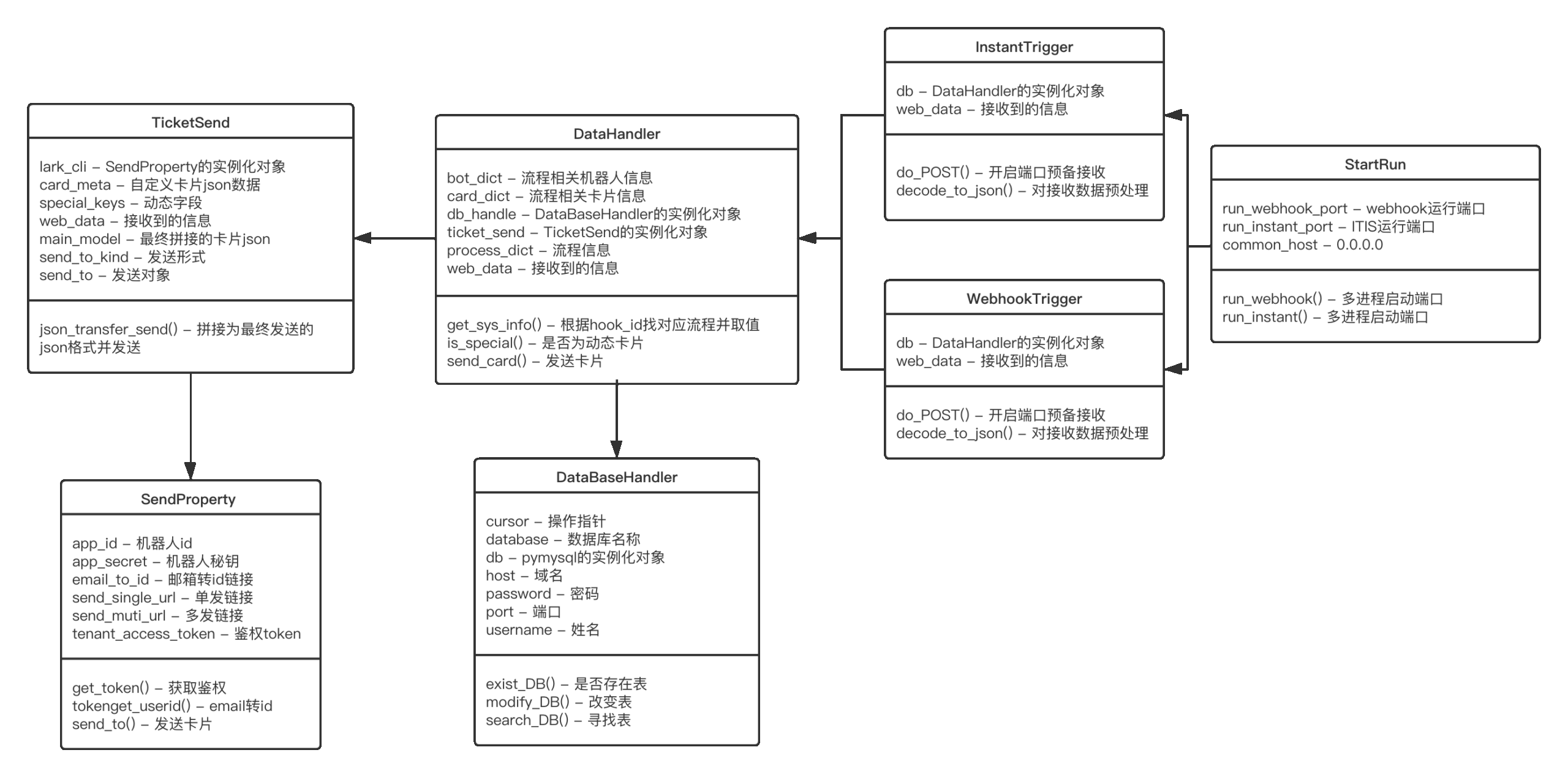
第一阶段UML依赖关系图
3、项目中遇到的问题&解决方案
3.1、BaseHTTPRequestHandler和HTTPServer的关系
开发中本来想用Python的多继承实现在启动网络服务的同时初始化数据库连接,即多个类同时继承BaseHTTPRequestHandler和DataHandler(自定义基础类),然后用多进程启用它们;但启动后各种报错,提示并未执行DataHandler内的__init__初始化方法;于是向上检查BaseHTTPRequestHandler的实例化过程,发现这个类是通过httpd = HTTPServer(server_address「host+port基础参数」, InstantTrigger「继承BaseHTTPRequestHandler的子类」)的形式实例化的,也就是通过HTTPServer类内部通过向BaseHTTPRequestHandler注入server_address的形式来实例化,此过程默认执行BaseHTTPRequestHandler内部的__init__初始化方法,所以我们需要用一种取巧的方法,在系统默认执行上述初始化方法之前,把我们的自定义类DataHandler的初始化方法「夹」在中间一并执行,所以最终InstantTrigger子类内的__init__初始化方法应该写作:
def __init__(self, *args):
self.dh = DataHandler()
BaseHTTPRequestHandler.__init__(self, *args)
其中BaseHTTPRequestHandler.__init__(self, *args)如果不写,系统会默认加在继承类的__init__首行,即为以下形式:
def __init__(self, *args):
BaseHTTPRequestHandler.__init__(self, *args)
怎么样,看上去是不是很像Java里的super()?以及由于HTTPServer父类不会主动实现(除非改源码)BaseHTTPRequestHandler以外的类的初始化方法,所以我们最终不得不放弃继承,转为依赖;这也从侧面映证了基于Python的OOP开发的一大特色:为了解耦允许动态绑定,优点是对开发者的宽容度高,缺点则是为了实现这种「便利」,Python的语义限制了它的性能。
3.2、json拼接相关
在这个项目开始之前,我还临时写了一个脚本来定期更新某个文档里的楼宇信息;实际上很多接口定义的接收值都是json,这也代表我们在开发中需要用到很多方法来动态拼接json并发送;而Python中实际上是不存在json这个概念的,它会转化为dict(字典)格式进行处理,以下皆使用字典来描述。
3.2.1、综述
无论是字典还是json,实际上离不开两种形式,其一为对象,其二为对象子类,以及他们的混合体:
{
"a": "123",
"b": ["1","2","3"]
"c": [
{
"x": "456",
"y": "789"
},
{
"x": "000",
"y": "111"
}
]
}
其中a、b、c都可以称为对象,a为字符串,b为数组,c为存放对象的数组;接下来的内容会讲如何对各种不同形式的对象进行动态操作。
3.2.2、合并两个字典
通过**取指针的方式合并两个不同key&value的字典:
dict_01 = {
"a": "s",
"b": "q"
}
dict_02 = {
"c": "t",
"d": "y"
}
dict_03 = {**dict_01, **dict_02}
需要注意的是,如果存在相同键,则会将后一个的值覆盖在前一个之上。
//dict_03的值
{
"a": "s",
"b": "q",
"c": "t",
"d": "y"
}
3.2.3、包含对象的数组
通过append()的方式将dict_05追加到dict_04中c键的数组内的对象中:
dict_04 = {
"c": [
{
"x": "456",
"y": "789"
},
{
"x": "000",
"y": "111"
}
]
}
dict_05 = {
"x": "222",
"y": "333"
}
dict_04["c"].append(dict_05)
3.2.4、子「字典」追加到父「字典」
直接赋值即可:
dict_06 = {
"d": "r",
"w": ""
}
dict_04 = {
"c": [
{
"x": "456",
"y": "789"
},
{
"x": "000",
"y": "111"
}
]}
dict_06["w"] = dict_04["c"]
//dict_06的值
{'d': 'r', 'w': [{'x': '456', 'y': '789'}, {'x': '000', 'y': '111'}]}
3.3、浅拷贝与深拷贝
若运用场景并非「每个变量只使用一次」,例如for循环为字典赋值,就需要考虑这个问题了;其中浅拷贝(copy)只会拷贝父对象,不会拷贝对象的内部的子对象;而深拷贝(deepcopy)为 copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
浅拷贝
dict_06 = {
"d": "r",
"w": None
}
dict_07 = {
"s" : []
}
for i in range(2):
dict_06["w"] = i
dict_07["s"].append(dict_06.copy())
//dict_07的值
{'s': [{'d': 'r', 'w': 0}, {'d': 'r', 'w': 1}]}
深拷贝
h = {
"content": [
{
"value": "abc"
},
{
"value": "efg"
}
]}
data_temp_content = {}
content_model_text_inside = {
'tag': 'div',
'text': {
'tag': 'lark_md',
'content': ""
}
}
for key_g, g in enumerate(h["content"]):
content_model_text_inside["text"]["content"] = g["value"]
data_temp_content.append(copy.deepcopy(content_model_text_inside))
//只能使用深拷贝,否则g["value"]作为子对象,append追加时指针还是指向同一处
3.4、日志模块
刚架设起来的系统肯定鲁棒性不佳,所以还需花费一些时间精力来优化和部分重构;为了更快地发现未知的漏洞,首先应该完善的是日志模块:
# 初始化日志模块
import logging, platform, traceback
log_dir = "bytedance/jira/bot/trigger/ticket_card.log"
if platform.system() == "Darwin":
log_dir = "ticket_card.log"
logging.basicConfig(filename=log_dir, level=logging.INFO)
通过识别系统自动定位日志所在位置,接着使用try-except捕捉错误并记录:
try:
# 此处植入需监听的代码块
pass
# 错误记录模块
except Exception as e:
error_meta= json.dumps(self.web_data)
print("机器人「" + self.bot_dict["bot_id"] + "」在发送卡片「" + self.process_dict["process_card_id"] + "」时出错,出错原因:「" + str(e) + "」,详细原因:")
traceback.print_exc()
print("接收到的信息:"+ error_meta)
logging.error("机器人「" + self.bot_dict["bot_id"] + "」在发送卡片「" + self.process_dict["process_card_id"] + "」时出错,出错原因:「" + str(e) + "」,详细原因:" + traceback.format_exc() + "接收到的信息:" + error_meta)
traceback模块会自动记录完整的出错信息,所以只用部署一处日志即可记录全局~
3.5、特殊字符处理
Jira的评论经常会出现一些\n、\r、\t之类的特殊符号,而这些特殊值如果不经过特别的处理,就会干扰到接下来的执行步骤。这里使用将\转义为\\的方式来避免json和string互转时的报错。
# 如果评论里有comment,判断是单行评论还是多行,如果是多行就需要换行
if "comment" in self.special_keys:
if "\n" in self.web_data["comment"]:
comment_temp = self.web_data["comment"].replace("\r","")
comment_temp = comment_temp.replace("\n\n","\\n")
comment_temp = "\\n" + comment_temp
self.web_data["comment"] = comment_temp
3.6、参与人对象的处理
这个需求算是比较特殊了,也算是让我明白了为何不能直接让jira与飞书对接的真正原因:更加细化的处理逻辑。在这个需求中,后端需要抓取最新操作人&最新添加的参与人,然后推去卡片发送。和上文1.5.2描述差不多,jira只能提供变化前和变化后的值,有可能这两者的补集是减去的人,有可能是新增的人,而且两个系统内的主键也不一致,飞书是邮箱,而jira是用户唯一key;所以需要通过哈希表来转换,这也是设计时比较硬核的一个问题:
# 如果special_keys里存在participant字段,提取新增的参与人信息组合进json
if "participant" in self.special_keys:
participant_info = self.web_data["participant"]
send_to_name_list = []
send_to_key_list = []
send_to_email_list = []
to_key = participant_info["to_key"].split(", ")
from_key = participant_info["from_key"].split(", ")
for ikey in to_key:
if ikey not in from_key:
send_to_key_list.append(ikey)
if send_to_key_list != ['']:
for ikey in send_to_key_list:
ikey_index = participant_info["all_key"].index(ikey)
send_to_name_list.append(participant_info["all_name"][ikey_index])
send_to_email_list.append(participant_info["all_email"][ikey_index])
data_temp = data_temp.replace("{participants_email}", ', '.join(send_to_email_list))
data_temp = data_temp.replace("{participants_name}", ', '.join(send_to_name_list))
self.web_data.pop("participant")
self.special_keys.remove("participant")
3.7、区别抽象卡片和具象卡片
抽象和具象的区别在于原始卡片模板中是否包含以下动态字段,如果有则进行替换操作:
# 有以下字段存在,证明有动态字段需要替换
@staticmethod
def send_remove(input_compare):
dynamic = ['send_to_plus', 'user_ids', 'user_id', 'open_id', 'email', 'chat_id']
return list(set(dynamic).intersection(set(input_compare)))
3.8、pymysql小技巧
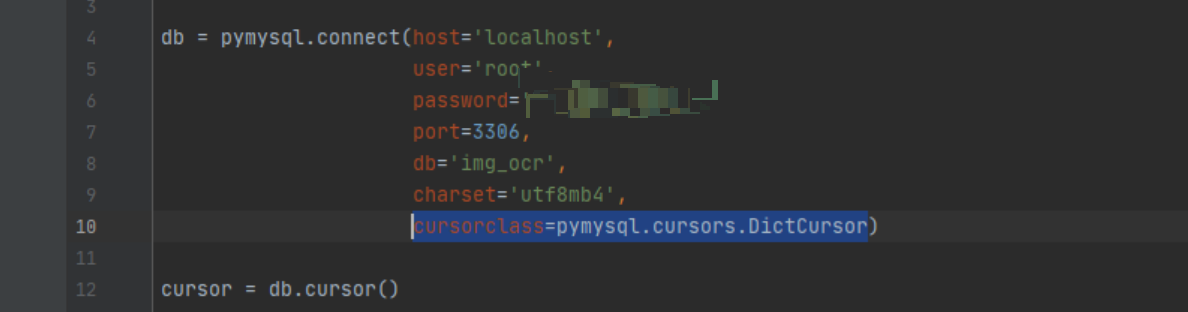
最近查资料的时候偶然发现的,原来pymysql中引入这个标识之后可以直接出字典:cursorclass=pymysql.cursors.DictCursor
4、重构相关
4.1、重构计划
经过了三四个月的业务熟悉,我发现架构中很多地方是可以优化的,比如流程和卡片完全可以统一成一个表,都是1对1,基本不存在1对n的关系;所以个人计划在完成需求2.3后,立刻着手重构。
4.2、淘汰代码
4.2.1、pymysql查库优化
# 取出表的键&值通过字典重组
def data_to_dict(info, col, name, dict_temp):
for k, i in enumerate(col):
_dict = {name + "_" + i[0]: info[k]}
dict_temp = {**dict_temp, **_dict}
return dict_temp
4.2.2、字段映射
# 状态转换
def status_transfer(statue):
ticket_dict = {
"等待支持中$Waiting for Support": ["Waiting for support"],
"已指派处理人$Assigned": ["Acknowledged"],
"审批中$Waiting For Approval": ["Waiting for Approval", "审批中"],
"采购中$Waiting for Procurement": ["Waiting for Procurement", "采购中"],
"处理中$In Progress": ["处理中", "In Progress", "Escalated", "Waiting for Solution", "Communicating", "Pending"],
"已解决$Resolved": ["Resolved", "已解决"],
"已取消$Canceled": ["Canceled", "已取消"],
"已领取$Received": ["In Use", "已领取"],
"已准备好,等待领取$Asset Ready, waiting to be picked up": ["In Preparation"],
"已关闭$Closed": ["Closed", "已关闭"]
}
for i in range(len(ticket_dict)):
if statue in list(ticket_dict.values())[i]:
return list(ticket_dict.keys())[i].split("$")
return [statue, statue]
4.3、代码复用与归档
动态卡片实际分为两种,一种卡片包含的动态字段,其他的卡片也是可以通用&复用的,另一种卡片的动态字段则是单独特供给这类卡片使用,所以为了解耦,降低每个卡片发出时所作的判断,故在此将上述两种替换方法从源类中拆出,独立为各自的类。
三、基于SpringBoot的ITIS项目维护
1、开发准备
1.1、git进阶之冲突的解决方案
一般情况下,造成冲突的本质原因都是当前文件和合并对象之间的不一致,为了解决这种不一致,需要用到合并,这里的合并和merge严格来说不是一种概念,前者是冲突合并,后者是非冲突合并,例如:
在项目中包含 A B C D 四个模块,我把A改为了E,小刘把D改成了F,那么合并还是照常,只有当我们同时修改A时(我把A改成了E,小刘把A改成了F),才会出现冲突;那么对于这种冲突,我们通过以下方式修复:
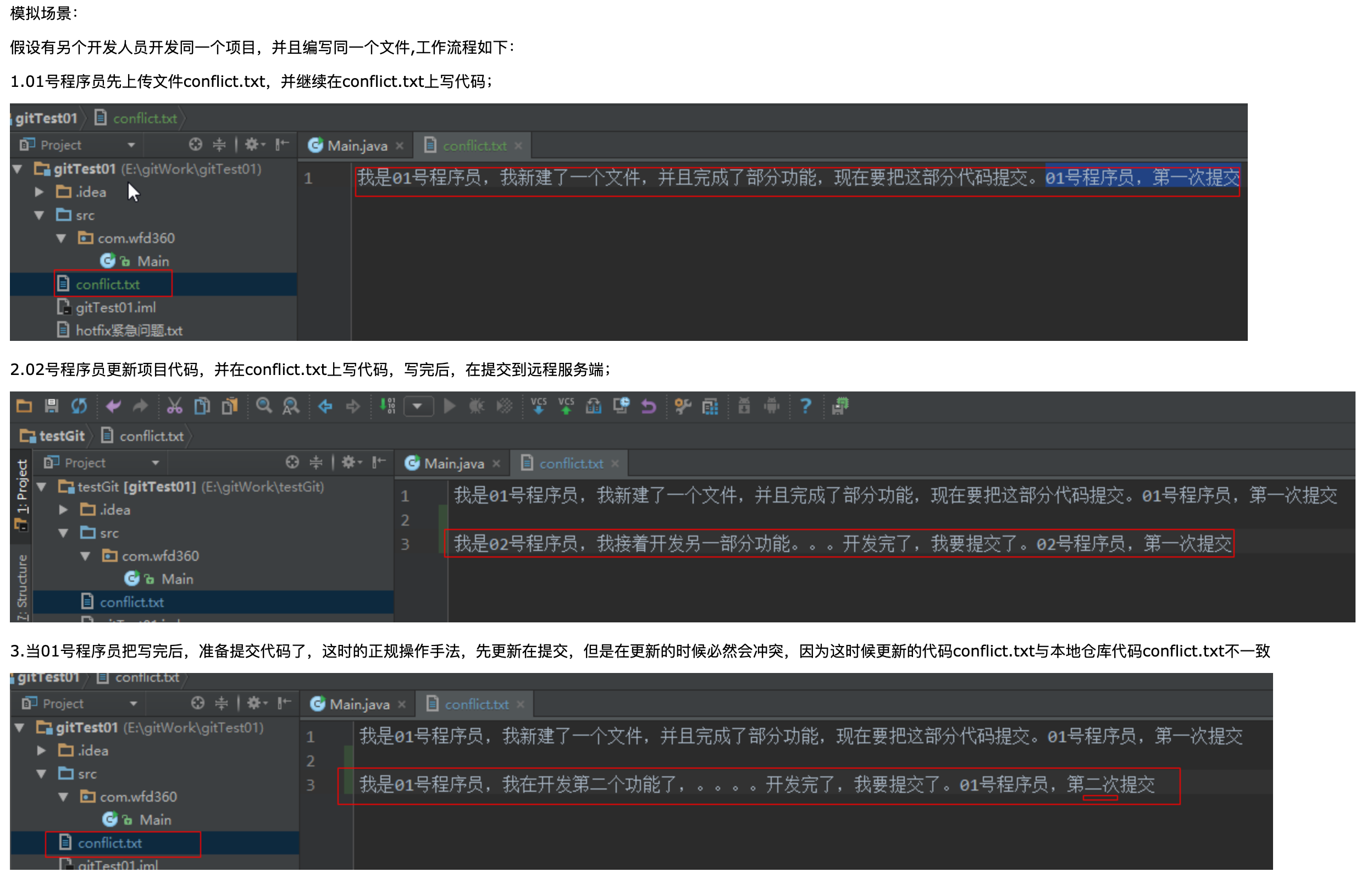
在提交代码时,由于本地端对远程的代码记录并没有改变,所以如果在fetch前贸然提交,系统直接报错push reject;此时需要先更新本地端对远程的代码记录,也就是fetch一下,然后合并的时候系统就会自动跳出这个界面:
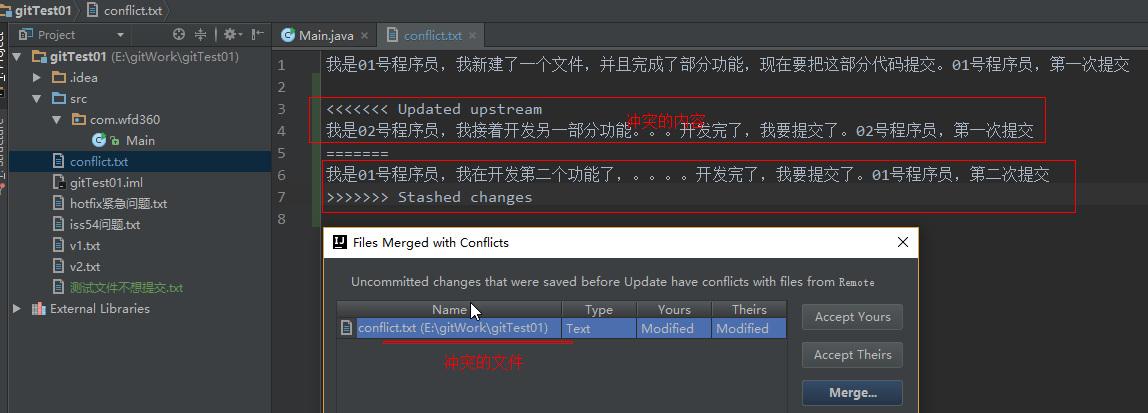
一般情况下选择merge,然后逐条逐条左合右合:
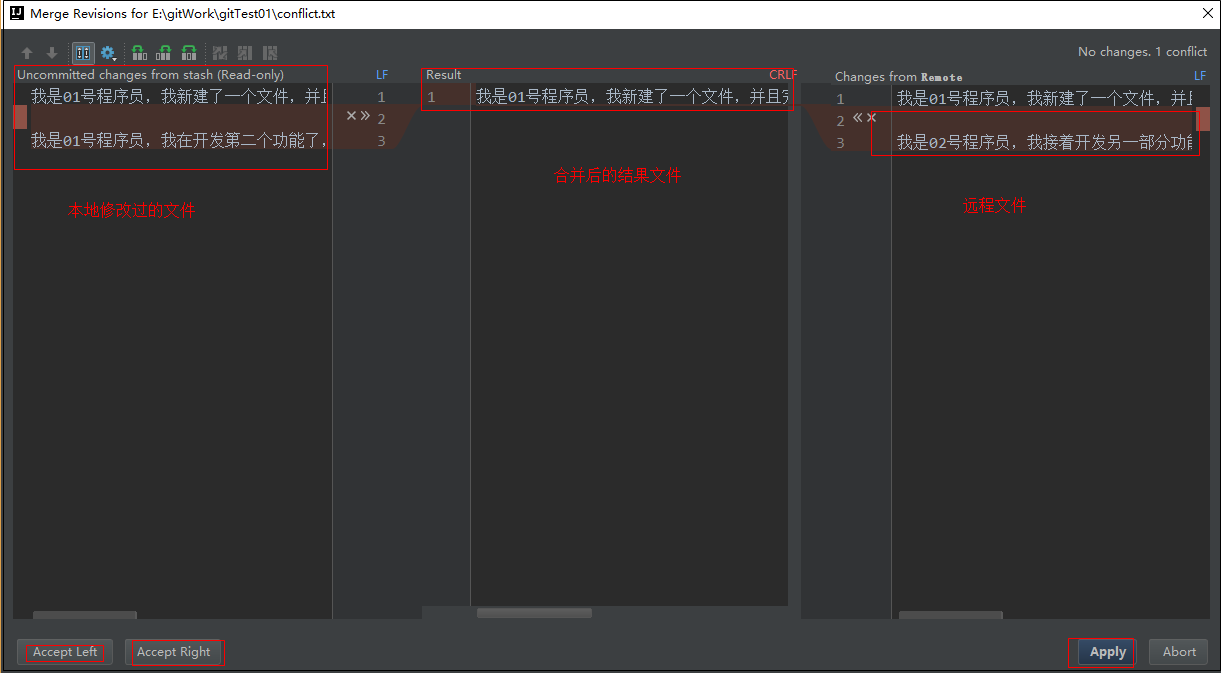
最后点提交,理论就会提示提交成功了;以上属于「先编写再合并」的情况,那么针对「先合并后编写」的情况有没有解决方案呢?当然是有的,那就是使用git stash来解决pull冲突;当需要pull的代码与本地编写的代码有冲突时,我们通过以下选项暂存自己的代码,然后pull正常拉取代码,接着unstash恢复暂存,若出现冲突手动merge即可。
1.2、Thymeleaf入门
模板语言的一种,除了用星号井号运算符等等方式特殊指代某个动态值以外,其脚本语言也是用的原生js语言,然后对于只学习了es6规范的我来说就看不懂了(尤其是一些接了$的方法名)……还有一些进阶的操作比如组件复用啥的就更搞不懂了;总之先看看大佬们是怎么开发的,先学学常用的语法,走一步看一步,不懂就问……
1.3、MyBatis入门
这个还勉强能看的懂,单表和树表原作者甚至提供代码生成,所以集中看怎么实现联表相关的操作。查了一下原系统中「用户-角色-部门」三者之间的关系,发现针对不同的联表查询,其实现方案大相径庭;比如操作内容仅限自表+需要和其他表的字段相比对,那么resultMap写自身的字段即可,如果操作内容需要包含其他表的字段+需要和其他表的字段相比对,那么resultMap需要包含相关连的表的字段。
1.4、疑问集中
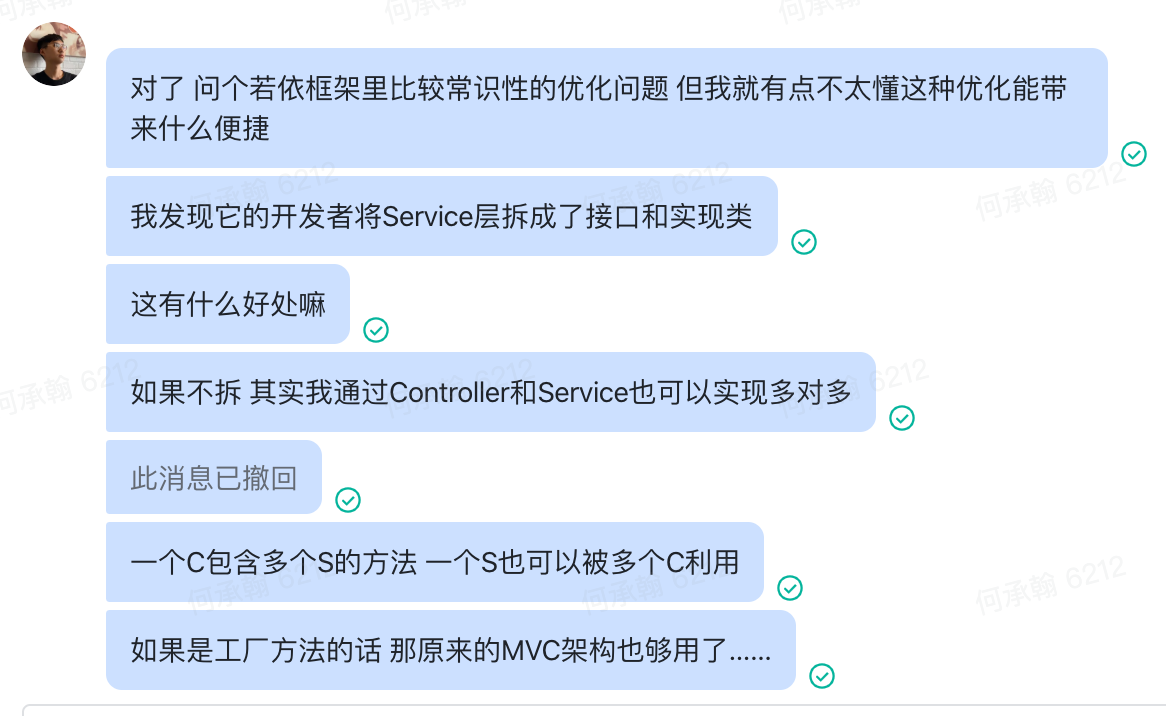
对于Java中接口与类的问题↓
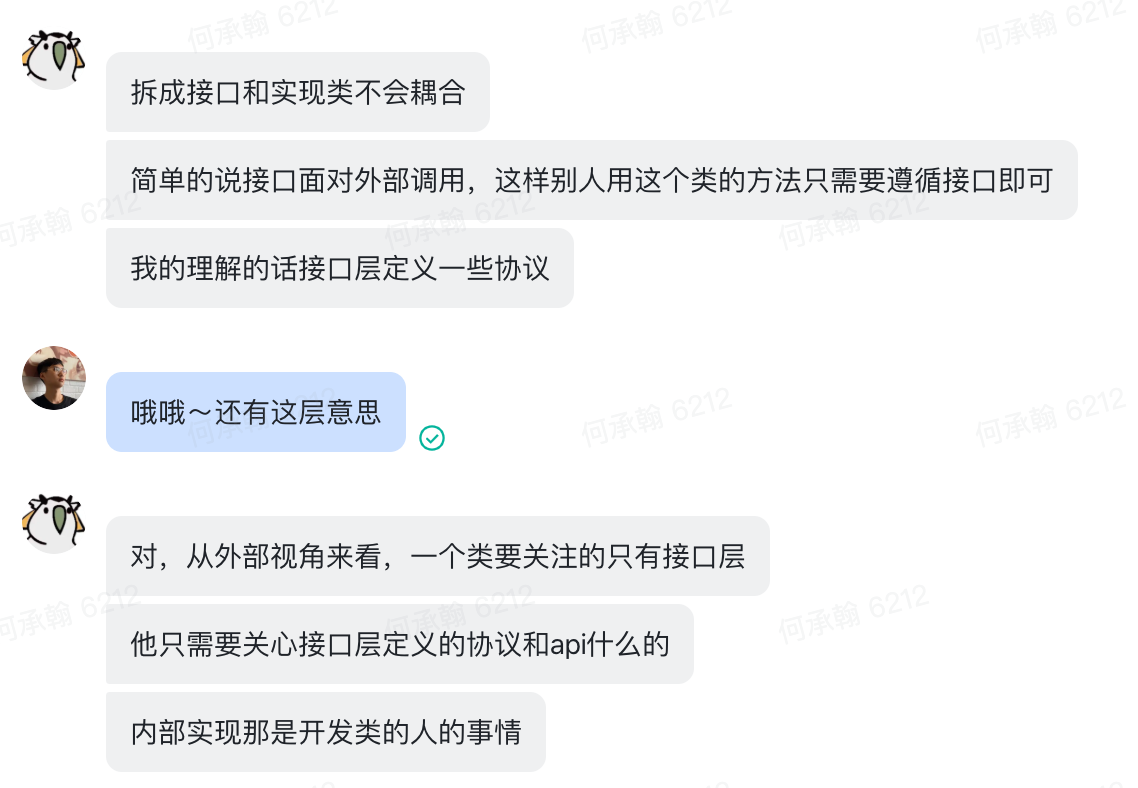
大神回复↓
关于前端模板↓
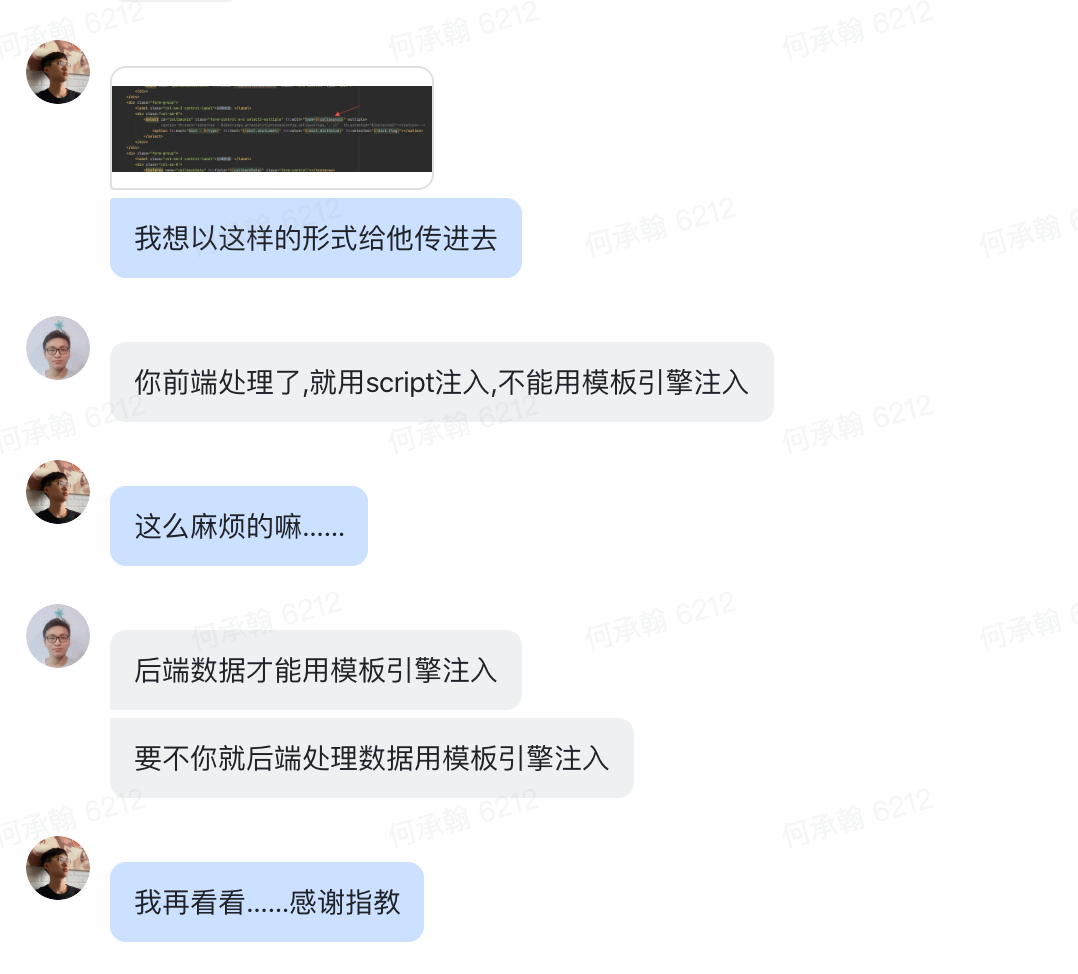
字典标签+下拉框+字段组合↓
Controller层:
/**
* 修改流程配置
*/
@GetMapping("/edit/{id}")
public String edit(@PathVariable("id") Long id, ModelMap mmap) {
ProcessConfig processConfig = processConfigService.selectProcessConfigById(id);
mmap.put("processConfig", processConfig);
mmap.put("bots", botConfigService.selectBotConfigByProcessId(id));
mmap.put("cards", cardConfigService.selectCardConfigByProcessId(id));
String[] type = processConfig.getCallbackType().split(",");
List<SysDictData> dictData = dictService.getType("callback_type");
HashMap<String, Object> label = new HashMap<>();
ModelMap mutiValue = new ModelMap();
for (SysDictData dictDatum : dictData) {
if (Arrays.asList(type).contains((dictDatum.getDictValue()))) {
mutiValue.put("callback_id", dictDatum.getDictValue());
mutiValue.put("is_selected", "true");
label.put(dictDatum.getDictLabel(), mutiValue.clone());
} else {
mutiValue.put("callback_id", dictDatum.getDictValue());
mutiValue.put("is_selected", "false");
label.put(dictDatum.getDictLabel(), mutiValue.clone());
}
mutiValue.remove(dictDatum.getDictValue());
}
mmap.put("label", label);
return prefix + "/edit";
}
Thymeleaf前端:
<div class="form-group">
<label class="col-sm-3 control-label">回调类型:</label>
<div class="col-sm-8">
<select name="callbackType" id="callbackId" class="form-control m-b select2-multiple"
th:with="type=${label}" multiple>
<option th:each="text,value : ${type}" th:text="${text.key}"
th:value="${text.value.callback_id}" th:selected="${text.value.is_selected}"></option>
</select>
</div>
</div>
2、流程管理开发情况
2.1、系统架构
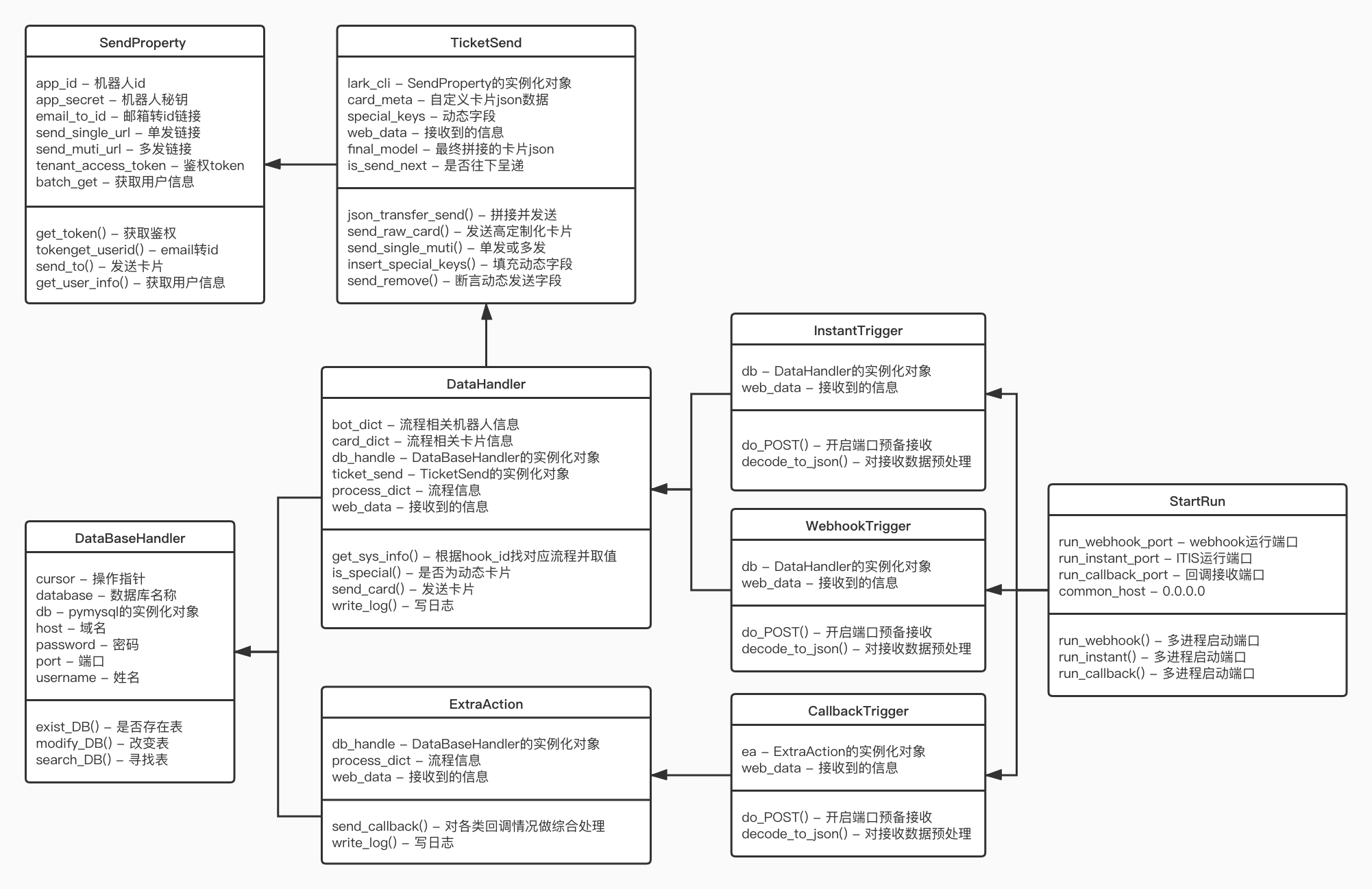
Python系统UML图↑
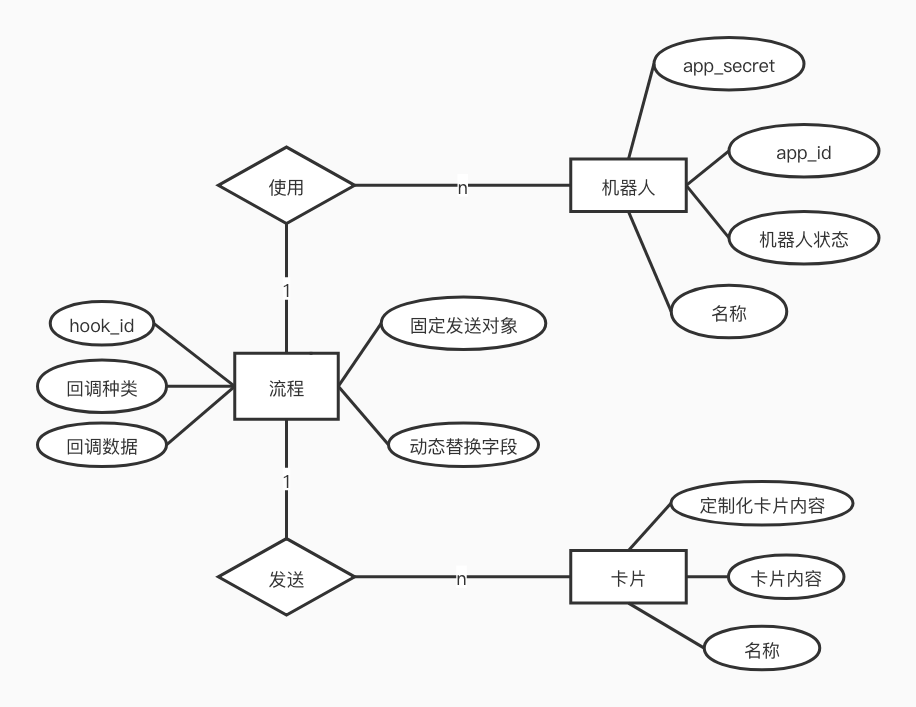
ITIS系统E-R图↑
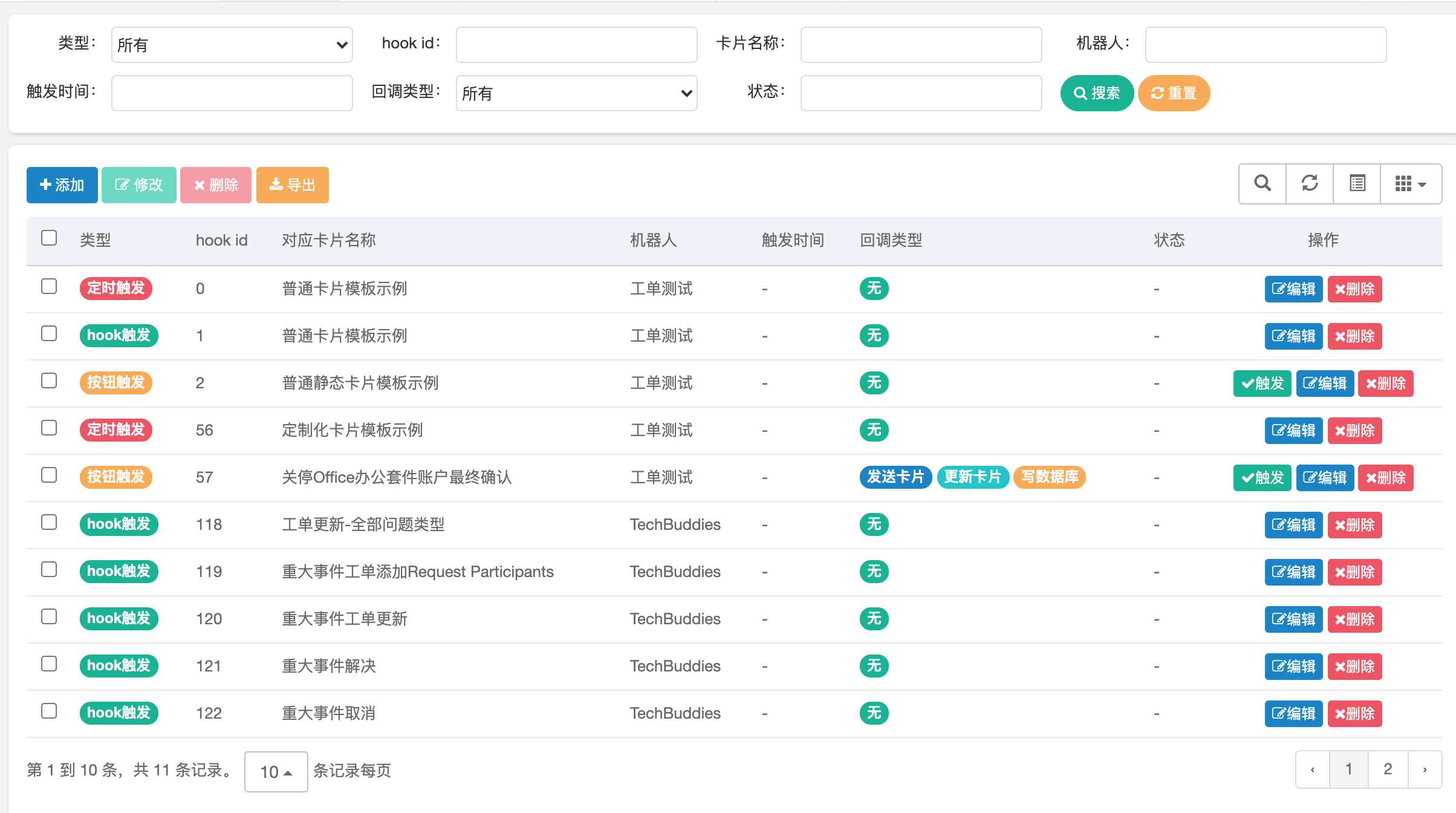
流程配置↑
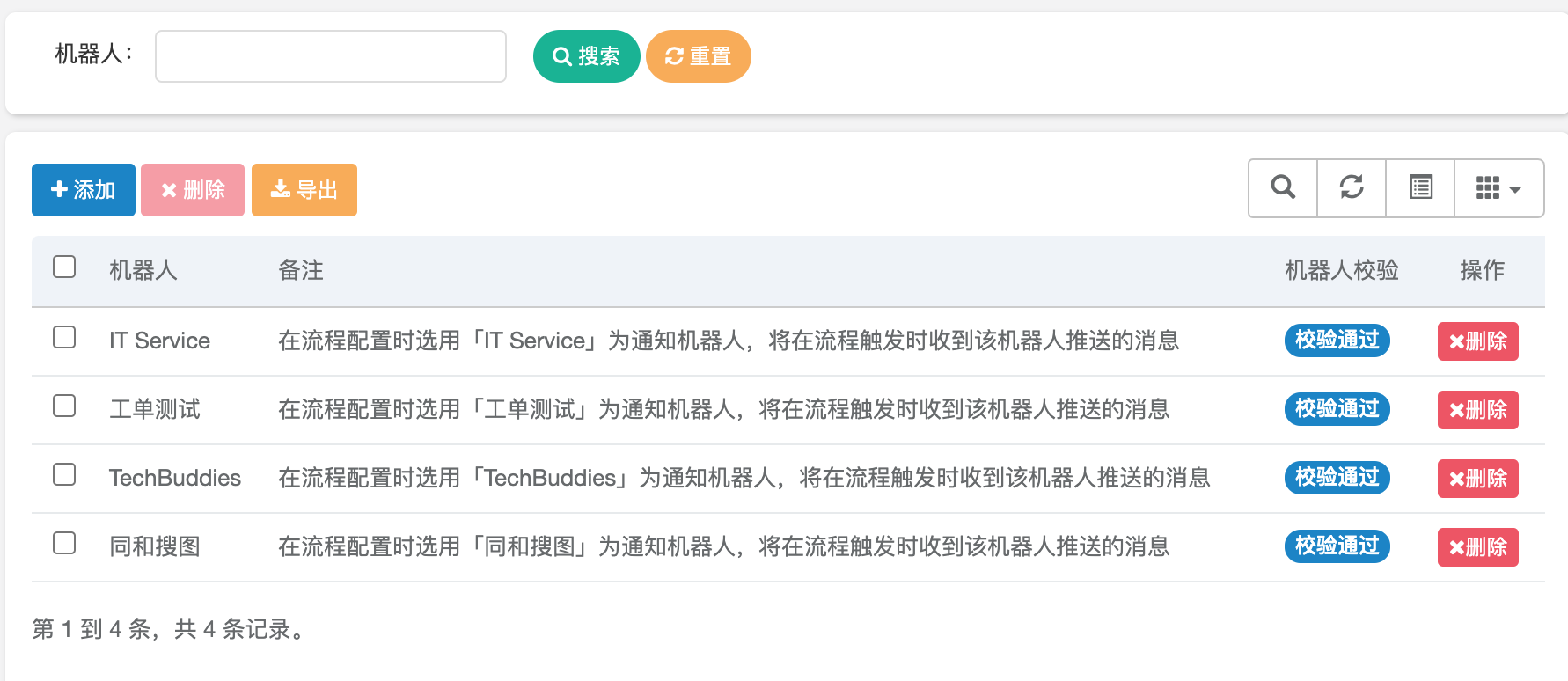
机器人配置↑
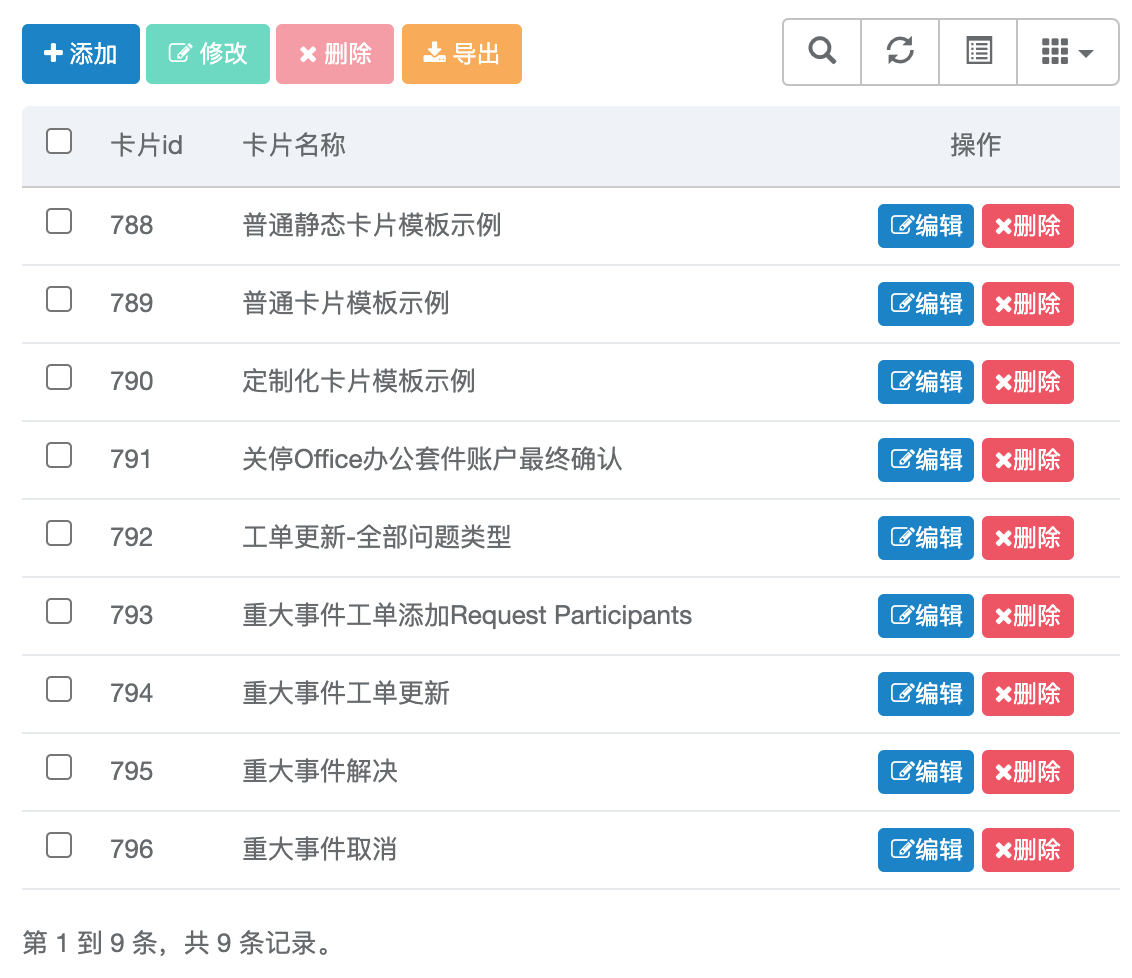
卡片配置↑
2.2、相关文档
工单综合处理后端-工作流接口&逻辑文档
工单综合处理后端-工作流框架
Jira工单通知卡片需求v2.2
何承翰 个人双周报
关停Office办公套件账户确认
2.3、重难点逻辑实现
2.3.1、校验机器人&触发卡片
在机器人被投入使用之前,首先应该校验其可用性,即以发送id和secret字段的方式;这和触发卡片的逻辑十分相似,都需要Springboot后端具备发送webhook的功能,所以我们用到了RestTemplate的方式来发请求;详细用法见:RestTemplate用法说明,需注意类似与数据传输有关的操作都放置在Controller层。
2.3.2、下拉框动态选择
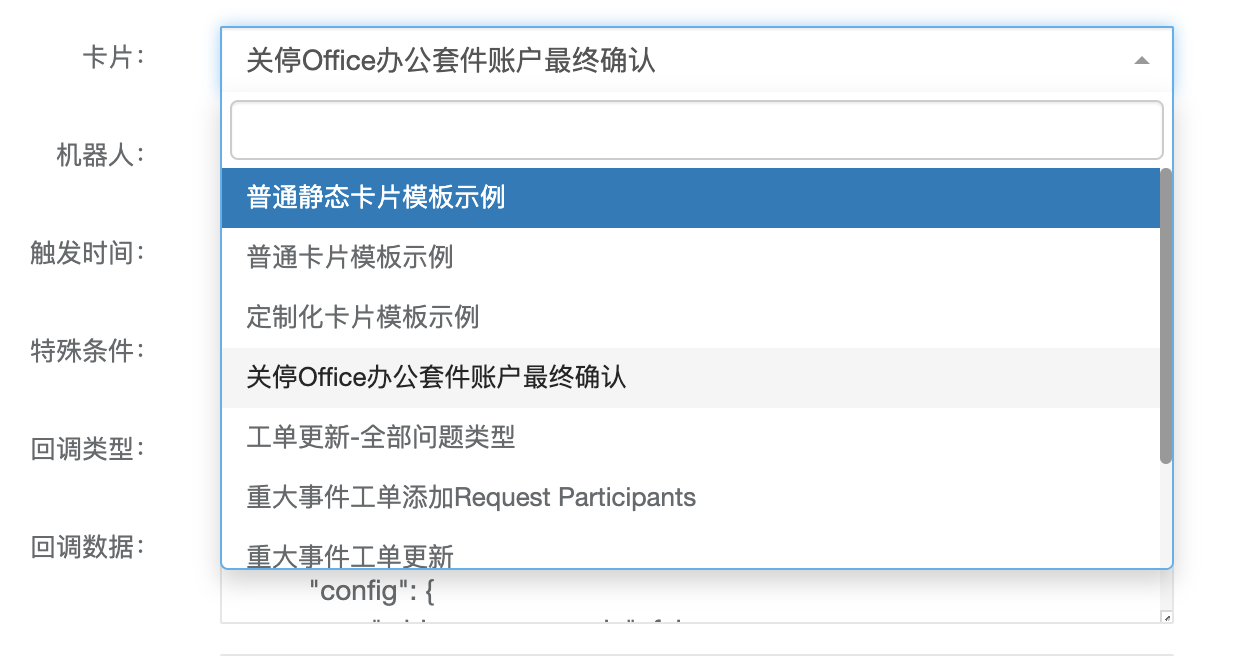
相当于是要在卡片下拉框中展示卡片表里全部的条目,接着还可以用搜索的方式快速选择需要的卡片;这一步就需要用到联表查询,mybatis配置如下(ProcessConfigMapper):
resultMap添加:
<association property="cardConfig" column="card_id" javaType="CardConfig" resultMap="cardResult" />
为cardResult新增对应的resultMap:
<resultMap id="cardResult" type="CardConfig">
<result property="id" column="id" />
<result property="name" column="name" />
</resultMap>
联表查询:
<sql id="selectProcessConfigAssociationVo">
select p.id, p.type, p.user_id, p.hook_id, p.hook_keys, p.card_id, p.bot_id, p.time_trigger, p.special_conditions, p.callback_type, p.callback_data, p.feedback, c.name
from process_config p
left join card_config c on p.card_id = c.id
</sql>
<select id="selectProcessConfigById" parameterType="Long" resultMap="ProcessConfigResult">
<include refid="selectProcessConfigVo"/>
where id = #{id}
</select>
Service层(BotConfigServiceImpl)处理:
/**
* 查询所有机器人配置
*
* @return 岗位机器人配置
*/
@Override
public List<BotConfig> selectBotConfigAll()
{
return botConfigMapper.selectBotConfigAll();
}
/**
* 根据用户ID查询岗位
*
* @param processId 用户ID
* @return 岗位列表
*/
@Override
public List<BotConfig> selectBotConfigByProcessId(Long processId)
{
BotConfig userBot = botConfigMapper.selectBotConfigByProcessId(processId);
List<BotConfig> bots = botConfigMapper.selectBotConfigAll();
for (BotConfig bot : bots)
{
if (bot.getId().longValue() == userBot.getId().longValue())
{
bot.setFlag(true);
break;
}
}
return bots;
}
Controller层(ProcessConfigController)处理:
/**
* 新增流程配置
*/
@GetMapping("/add")
public String add(ModelMap mmap) {
mmap.put("bots", botConfigService.selectBotConfigAll());
mmap.put("cards", cardConfigService.selectCardConfigAll());
return prefix + "/add";
}
Thymeleaf前端:
<div class="form-group">
<label class="col-sm-3 control-label">机器人:</label>
<div class="col-sm-8">
<select id="bot" class="form-control m-b">
<option th:each="bot:${bots}" th:value="${bot.name}" th:text="${bot.name}" th:selected="${bot.flag}"></option>
</select>
</div>
</div>
2.4、迭代工作
(详见工单综合处理后端-工作流接口&逻辑文档 第六部分)
定时触发
前端可视化配置
旧工作流的迁移
3、和「消息通知平台」开发团队的沟通
第一次和其他部门的开发者对线,感觉自己还是太菜了(咳咳
首先是找到他们的PM,大致介绍了一下我们的平台和功能,接着她就把我和他们开发mentor拉到一起聊;他们表示未来不排除以各种各样的形式接收发送卡片的服务,不过由于开发性价比相关的问题,他们也得把开发资源投入到更common的需求中去。
不可排除的是,目前对接jira系统webhook的需求,确实是我们这边较为独特的服务,贡献出的代码也的确对他们未来的开发有一定帮助(比如设计自定义字段、接收回调value等,他们目前使用Django REST framework);但他们最终的目标是通过轻服务(https://qingfuwu.cn)改变公司内部平台与平台之间的传统交互关系,从API交互改为severless上下文传递,牺牲运行成本提高开发效率;其大致逻辑如下:
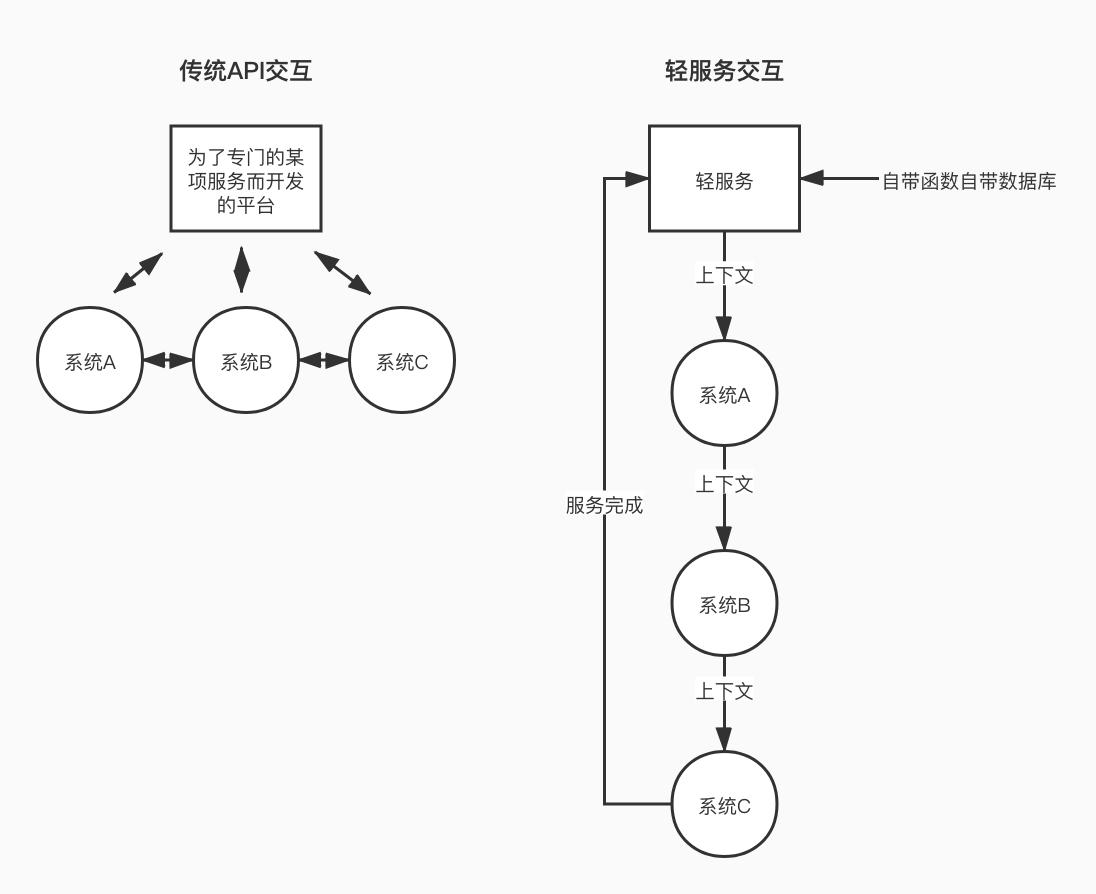
每一个现有的系统都扩展一个与之相对应的轻服务接口(SDK),然后新定义的需求服务(轻服务)就在这些SDK之间滚动就行了;在他们的设想中,未来无论是jira系统还是消息通知系统,都可以当做一个轻服务接口,而设计出的具体通知,则可以当做轻服务;这个设计当然很美好,但感觉距离现在还是有些遥远……尤其是他们邀请我开发,但我却没法加入的时候:
就目前情况而言,我们现在这套系统应该是够用的,尤其这套系统是针对ITIS相关需求设计的,别的部门也没这么多内部通知要发;而且对于目前IT部门的通知需求而言,隔三差五人力添加也不会很麻烦(比起以前针对一个服务就要写一个脚本那可真是方便太多了),所以感觉这个前端需求或许等他们用轻服务打通全公司各种内部平台之后,再和他们合作开发。
消息推送平台:https://notify.byte\dance.net/bot_add
消息卡片搭建工具:https://open.feishu.cn/tool/cardbuilder
4、有关Think Creativity的思考……
自从进入公司,得益于平台的优势,在机缘巧合之下我认识了很多大佬,同时也经手了不少项目,这些项目有公司内部的,也有外部的(公益开源类);功能各异,所涉语言繁多,项目架构也五花八门……很多时候就有一种感觉:自己被陷进去了……不是说这些项目不好,反倒是应该说,正是因为这些项目太优秀了,逻辑太过缜密,所以当你接受了某个项目的逻辑,之后再去维护、二次开发这个项目的时候,也会使用相同的思考方式去对待,这就导致我们的思维无法被发散,也就很难做到「Think Creativity」了。记得好友Mars对我说过,无论是多么复杂的程序,其底层实现都是0与1的逻辑运算,计算机科学就是一个用非常简单的步骤去解决一个非常复杂问题的学科,无论是编程还是架构,究其根本都会把一个非常复杂的问题逐步转化为一个个简单步骤的过程。
作为职场萌新,我写出的代码和大神们写出的代码,其差距究竟在哪?有很多人会抱持这样一个观点:我会用语法糖,我会用装饰器,我会用迭代器……那我就算师出有名了。对于这个观点,当我真正参与工作、走进真实的项目中之后,反倒是有了新的理解;记得一年前参加实训的时候,我们尝试用vue框架写前端,其中需要给某个json的value批量赋值,我看老师教的是for循环,但网上更优的方案是通过object.keys(你要赋值的数组).forEach(key=>{针对每个迭代值的操作})这样的迭代器方案实现的,然后我就去问老师,你为什么不教同学们用这种比较精简的方案,然后他接下来讲了半个小时,那次谈话可以说让我毕生难忘——他从迭代器的底层给我讲起,详细分析了数据分别通过两种方式传入后经过了哪些处理步骤,在堆里新增了什么内存块,指令又是如何在栈里被调用的……并指出了es语法标准的种种弊端,最后得出一个结论:使用最原始的for循环,其性能是比迭代器要更好的(当然他也加了一个限定语,在js里是这样的)。
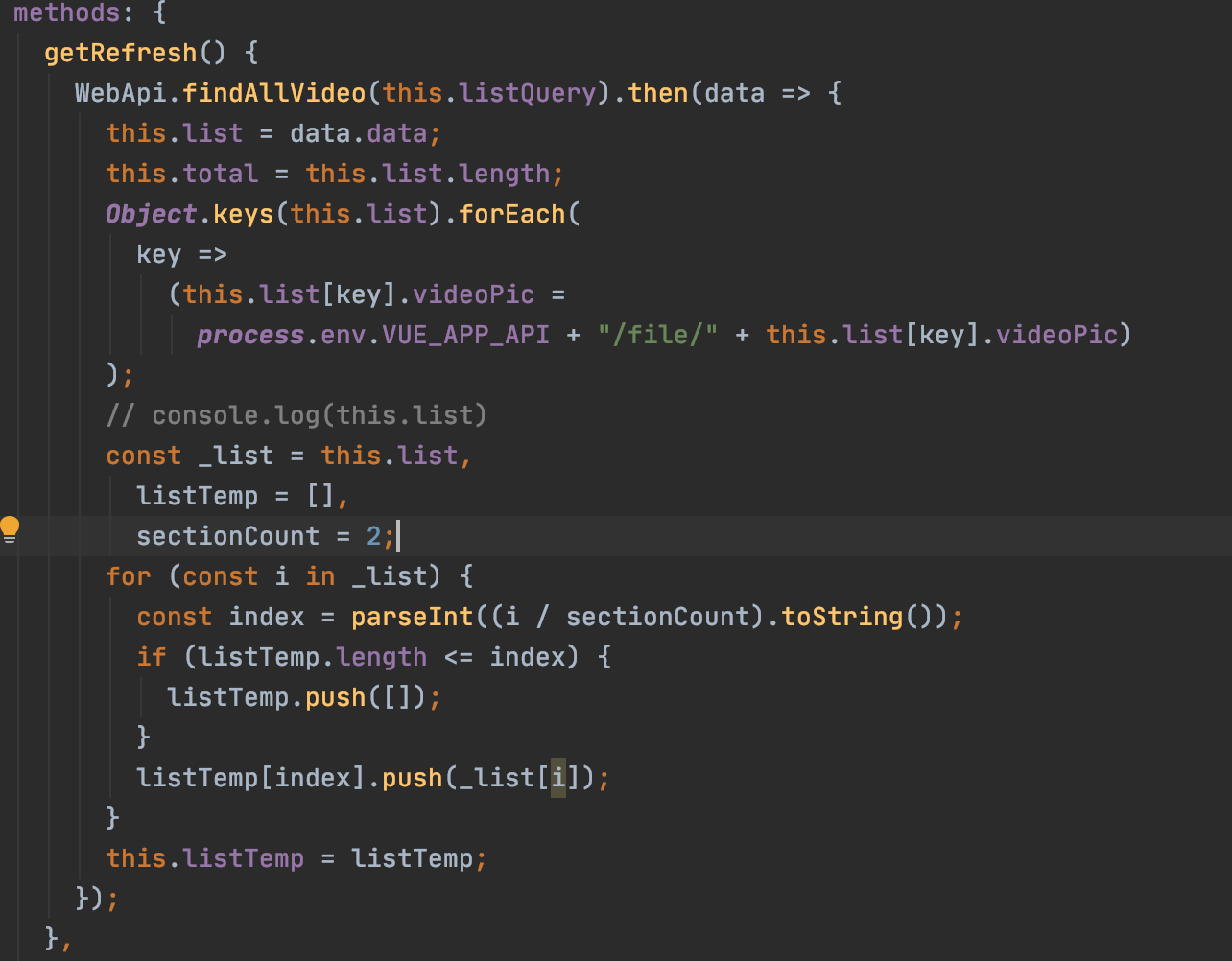
从那次开始我才开始渐渐领悟到编程的本质:代码运行效率、代码可读性、代码架构好比为三角形的三条边,而这个三角形的面积,就是开发者的能力。在过去我可能会嘲笑一个在vue框架上用原生js做开发的开发者,但从现在起我反倒是会非常敬佩这样的人,毕竟前端本身就极难上手,尤老大所作出的贡献只是降低了开发者的门槛罢了,而这种降低,实际上是以牺牲性能为代价的。所以真的该嘲笑的,是当时那个不懂js语言基础的自己。
无论是语法糖、装饰器、迭代器等等花式代码开发,其本质都离不开最基本的原子操作:if-else、for&while循环、类的继承与多态、接口的实现与复用……当我意识到这一点的时候,才发现真正决定编写一段代码时是否真正做到「Think Creativity」的,正是上述的三角形。好了,让我们回到最初的讨论:每一个项目都有自己的固有开发思路,所以半途加入后很容易被牵着鼻子跑;要么按套路重构,要么按套路新增模块——这对于解耦于事无补,甚至还会继续增大项目的臃肿度……唯独只有重写这个项目才能摆脱这种看不见的「路径依赖」,适应新的需求;这就好比,当一个项目足够大以后,它本身已经形成了一种「内联体系」,「三角形」的面积已经定死了(果然十分具有稳定性),想要扩展这个面积,只能另起炉灶……这也算是对「造轮子」的新理解吧,为何新的框架层出不穷,为何新的概念推陈出新,大概是我们都在不断突破,不断「Think Creativity」吧。
上个周末和大三的师弟聊天,他说字节跳动的面试题大概是面向应届生招生的所有大公司里最刁钻、最离奇的,我说,你看看头条系的产品就知道了,头条旗下的app无论是设计还是功能,都极度富有创意和想象,而真正能够支撑起这些的,只有不断深入底层探索的精神和过硬的技术,有些题目说不定就是改编自实际开发中的问题,这都是很正常的。也许在别的公司,你懂一个框架六七成你就能实际上手开发项目,在头条,可能你要懂八九成。
有的时候我路过同事们的工位,看到大家其实都在开发和后台相关的功能,都在负责内部的工程(*.bytedance.com)一类的项目;然后就开始思索,一群社会精英们写的crud,和一群从补习班毕业的人写crud,到底区别在哪?但当我真正使用相关的内部平台、实际阅读开发源码的时候,才发现其中的本质差别:更加人性化的交互、更加清晰明了的业务框架、更快捷的响应速度……这些都比外部的同类型产品好了太多,比起普通公司、市政单位、甚至我自己曾经开发过的项目都不知道优秀多少倍……
记得前几天看ceo面对面,震原和定坤说「做成一件事真的太难了」,开发世界无易事,「随便一个能用的产品的背后都堆积着数不清的人力物力」在这个行业中司空见惯;看似很简单的功能的背后都有着不菲的资源支持。想要真正在这个行业有所建树,肯定会牺牲掉自己生活的其他大部分时间精力,那么在这个基础之上,如何在有限的资源里尽可能多地「Think Creativity、Inspire Creativity、Do Creativity」,是我彼时彼刻需要多加思考的最大问题。
四、话术优化项目
1、 原型设计
项目简介:「Textexpander话术优化更新」项目需求
由最终的结果倒推需求:textexpander输出动态语句→不同的动态语句需要在不同的时间插入不同的话术中不同的地方→按类别划分语句、按时间激活类别、按接口归档类别→接口1对N类别,类别N对N语句
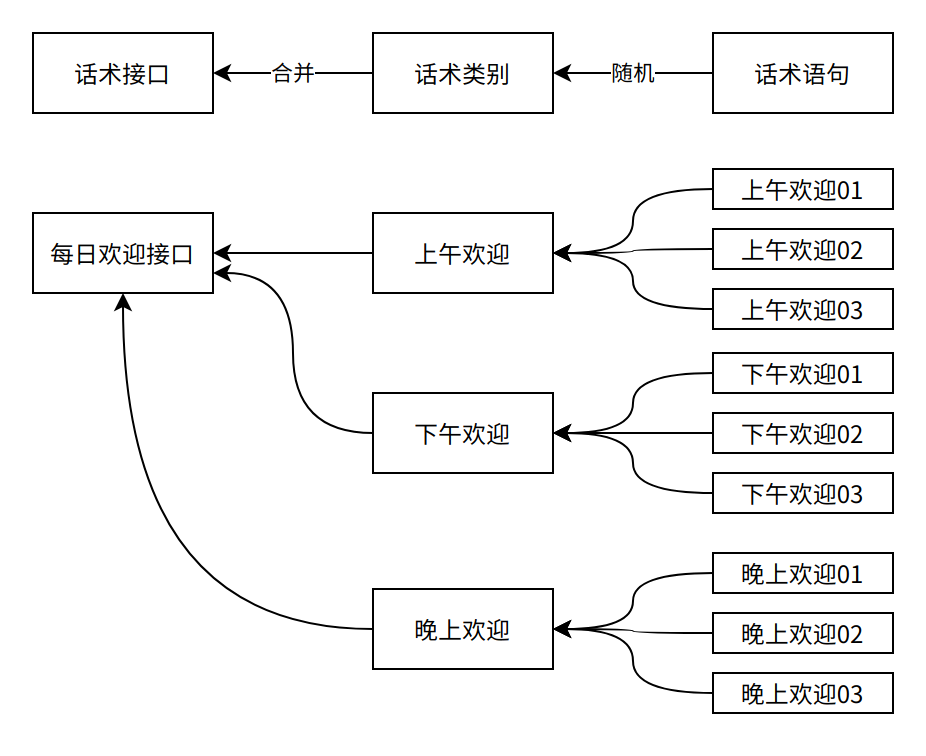
2、具体架构
其中,不同时间激活不同语句的实现逻辑为每隔一小时遍历所有类别,并根据当前时间判断激活态。该更新算法通过若依框架中的quartz定时模块实现,通过基于python的Flask框架响应网络请求。
主要问题还是集中在前端,如何让用户快速理解并上手这样相对复杂的应用,有些用户体验确实需要深思熟虑,比如当数据量变大之后,如何防止使用者越用越乱,是需要根据不同的条件归类和关联的。
2.1、对于debug的一些新思路
过去可能对于bug的态度会比较执拗,非要靠自己从逻辑上看出问题来;其实在高效的开发过程中,这是没有必要行为。很多问题如果靠人眼看,一步步梳理,常常十几分钟就耗在这个上边了,非常不划算;而通过IDE自带的debug工具,对出问题的段落打断点,靠程序来帮你梳理,那么这个速度就快很多了。所以今后遇到bug,都按以下这个标准来处理:
定位出错段落→给1分钟时间自己梳理逻辑,能找到就找,找不到立刻放弃这种方式,打断点→给最可疑的地方断点,一步步调试(首先step over过一遍,step over解决不了就针对出问题的间隙step into)→若查不出问题,再通过自己的判断选出最有可能出问题的几个点,依次断点调试→如果仍然解决不了,按照写代码的逻辑过一遍,10分钟内未解决,求助大佬一起看。
2.2、多对多的表关联
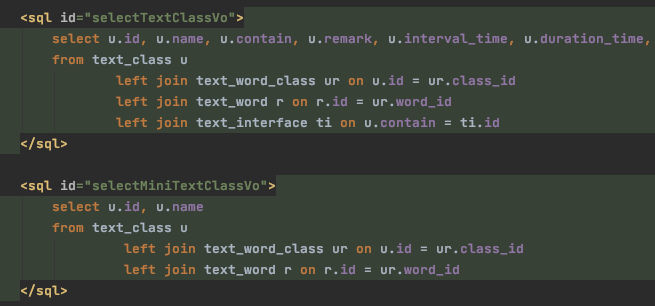
关系型数据库经常会出现这样的关联模式:一对一、1对N(或N对1)、多对多;其中一对一就不必说了,能放一个表就决不放第二个,一般不会出现;1对N我们也做的比较多,一个衣柜里放N件衣服、一个网红被N个人关注等等,这种情况下只需要考虑子表的关联查询即可(即查询子表条目时返回对应的父表字段,通过父表条目可以归档其拥有的所有子表),但是有些比较特殊的数据关系,可能会涉及N对N,这个时候就需要中间表来帮助处理了,它会收录两个表的主键,对具体关系进行操作时,首先要修改此表;而对N-N的表做查询的时候,也需要join此中间表。
3、用户体验
……老谭让我耗子尾汁
这个我真的该好好想想,因为之前都是做甲方工作,只有让用户来适应我,基本不用考虑怎么去让用户使用得更方便……然后做出来的东西就被各种吐槽「只是能用,但并不易用」。到下个月,我进公司就满半年了。其实刚进来的时候我就知道自己在这方面存在问题,但不甚明了;经过这小半年的打磨,可以说了解了不少,也明白了「做功能简单,做好功能不简单」的道理。好的功能不仅仅要求RD明白需求,更是一次次功能迭代时打磨出来的。尤其是IT部门,其每一件产品都是为了提高生产效率而打造的,这就要求我们更加贴合使用者的逻辑和习惯。所以在原型设计的时候,应该养成除了考虑产品逻辑,也要站在用户侧,把用户体验也考虑进去的习惯。对于已经进入后期维护的项目,在维护过程中不断调研用户的体验,并不断更新改进;对于正在开发的项目,要不断和用户沟通,从近似的项目中找相同点,多参考以往表现优良的项目的底层设计。
归纳一下,实际上用户体验可以抽象成:让用户以最小的操作成本和最直观容易理解的
4、针对大量数据的管理方法
正常来说,对于数据量不大的模块,我们可以通过传统的CRUD来解决;但是当业务数据量不断扩大时,每次单个单个的维护数据的效率就十分低下了(尤其是简单数据)。这个时候,就需要通过文档的方式来维护数据,并且设置同步相关的操作(终于知道为啥Excel表这么受欢迎了,同时也知道这款产品根治的是什么样的使用痛点需求)。可以看到我们IT值班号线上工程师的排班班表就是通过这样的方式来管理的,这也为TL管理数据带来了便捷。
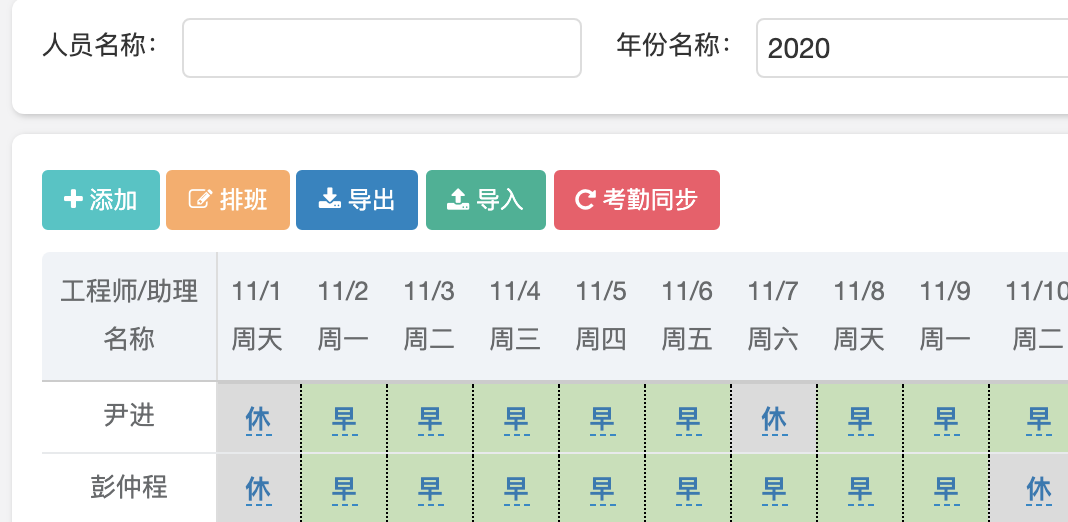
综合各项需求来看,实际上最理想的管理形式应该是:在系统中的修改可以实时同步到文档,在文档中的修改可以实时同步到系统,这样无论是哪种颗粒度的修改都可以被兼容。
多元兼容🙃
5、项目中遇到的问题&解决方案
5.1、Flask+pymysql采坑
众所周知,Flask是不能放在类里边使用的(详情参看:https://stackoverflow.com/questions/40460846/using-flask-inside-class,大致意思是说Flask本身就是以静态类的方式初始化的,即一个服务内不可存在多个Flask应用),这就导致了很多的隐患,比如只能在方法中初始化其他模块,如果在方法外初始化(即全局初始化),好比这次初始化pymysql,就会造成模块冗余,明明cursor执行了查询方法,mysql数据库里对应表的数据也不断在变化,可返回的值却仍旧是固定的……只有在方法中走完pymysql的生命周期(初始化连接→查询→关闭连接),才能实现查询内容的动态更新。
5.2、OKR
这个双月正式开始写okr,果然对工作的安排很有帮助:
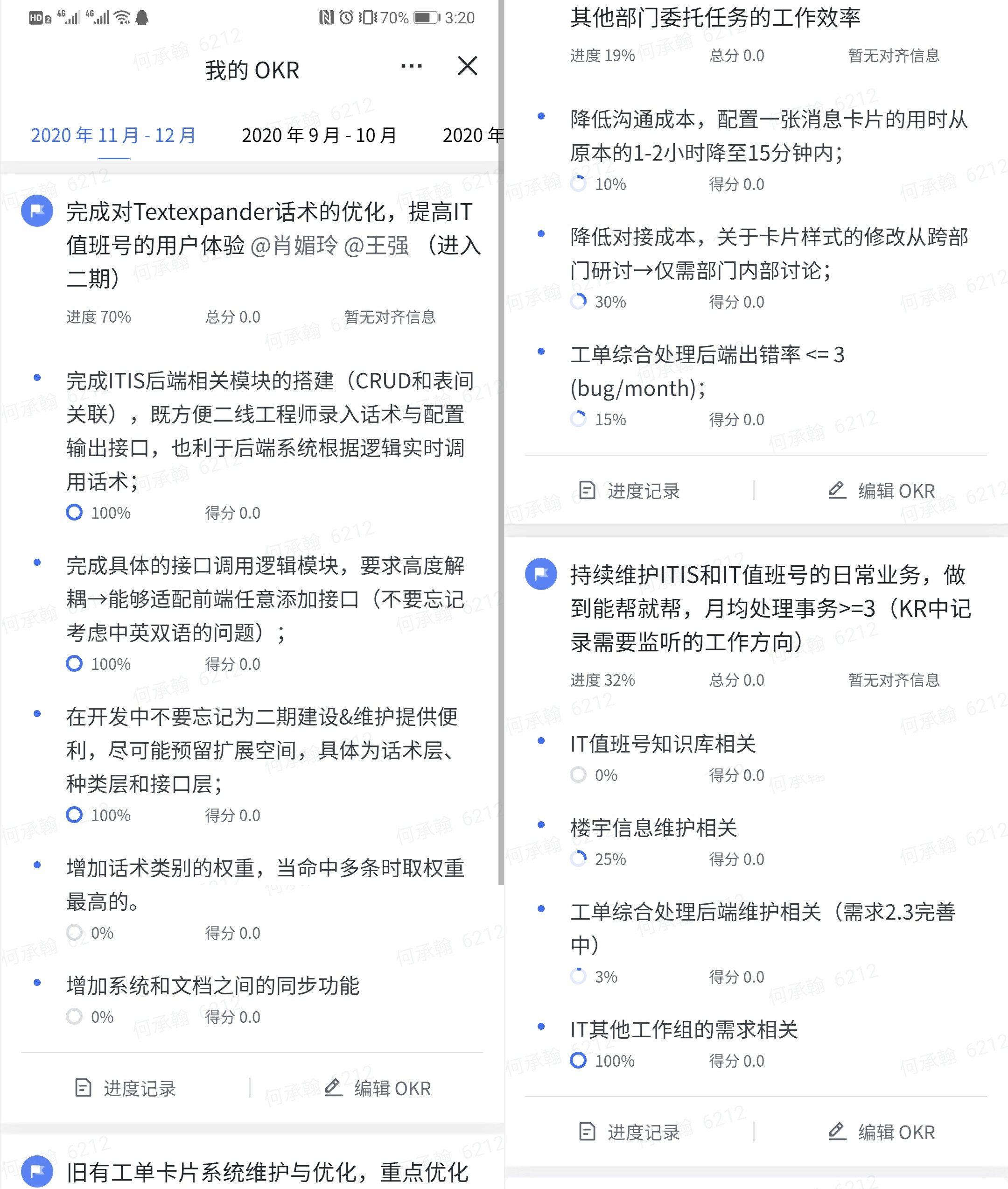
目前阶段工作安排:
新增话术同步
售货机小程序
将工单卡片模块的两个模块(卡片+流程)合并、解决不选回调时的bug、增加jira_auto存储字段
五、第三方售货机硬件服务的对接
一句话,第三方对接进来,如果要考虑通信安全问题,设计出来的逻辑就非常容易让人脱发……听说IO和EI的人也花了很长的时间理解这套逻辑,这样我就放心了(至少没有证明我的理解能力比别人差……)
1、原型设计
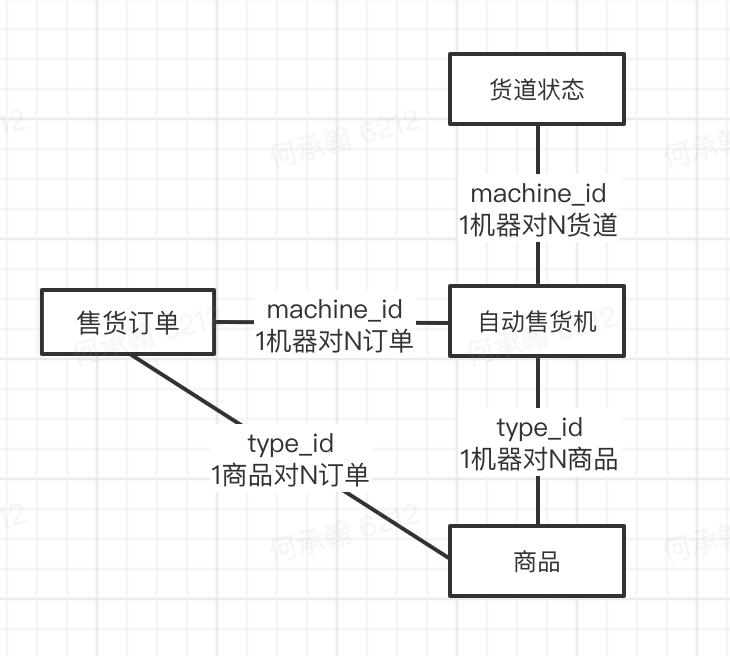
关于第三方平台&IO的文档全部都在这里了: https://byte\dance.feishu.cn/drive/folder/fldcnTFXdK3k2FzCxex3sraCRRe
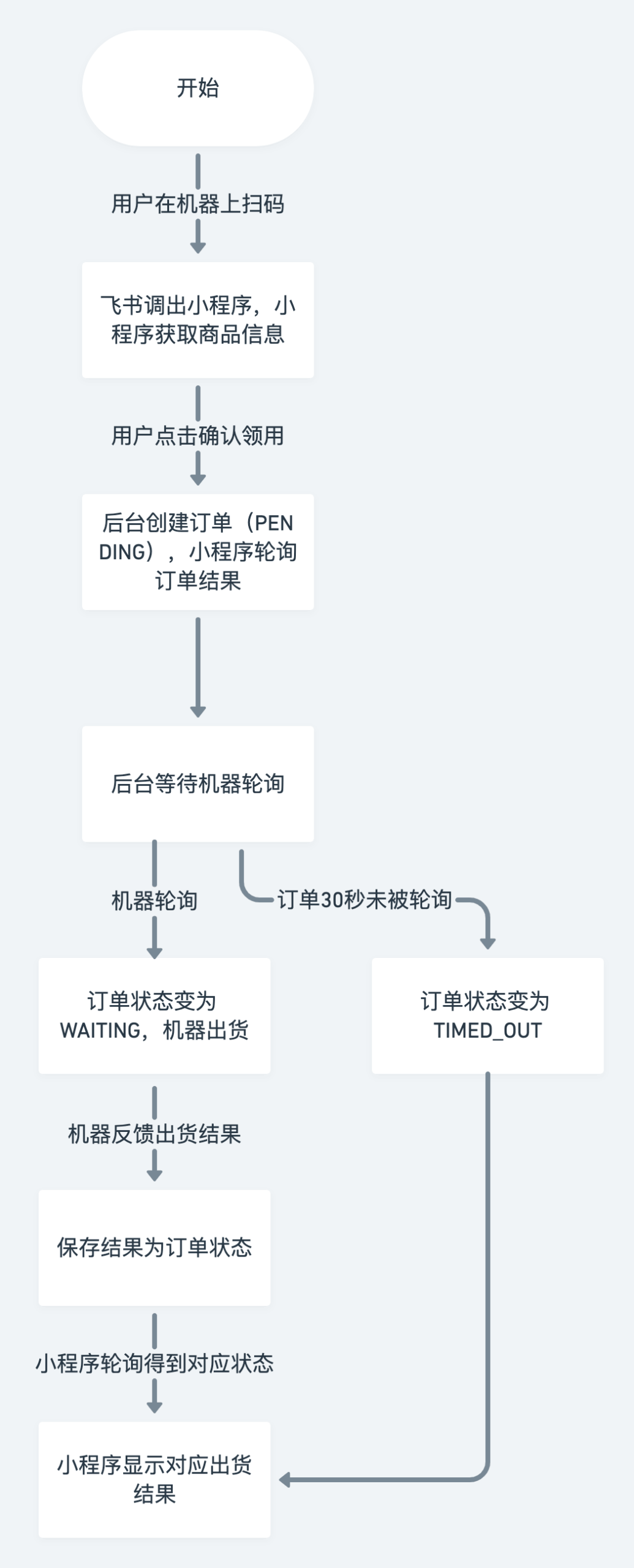
2、框架集成
本次开发使用了python-flask作为后端,小程序作为前端,其中由于框架特性,普通https和ws请求是分开的(两个脚本部署到两个端口上,分别解析到两个域名);小程序也是用原生框架和语言写的,虽说我们的飞书小程序可以引用微信小程序的组件库,但还是有很多语法和定义是不支持的;还好得益于各部门大佬们的协助,总算有惊无险地在排期内完成任务;
记录一下开发中容易迷惑的点,比如websocket众所周知并非轮询而是监听,但通常的代码却是:
| Python
@sockets.route('/test_ws') def test(ws): while not ws.closed: #你要执行的内容 |
乍一看好像是不断的循环,实际上这里边隐藏了一个「阻塞」的属性,websocket的核心其实也是tcp的socket,我们来看看源码:
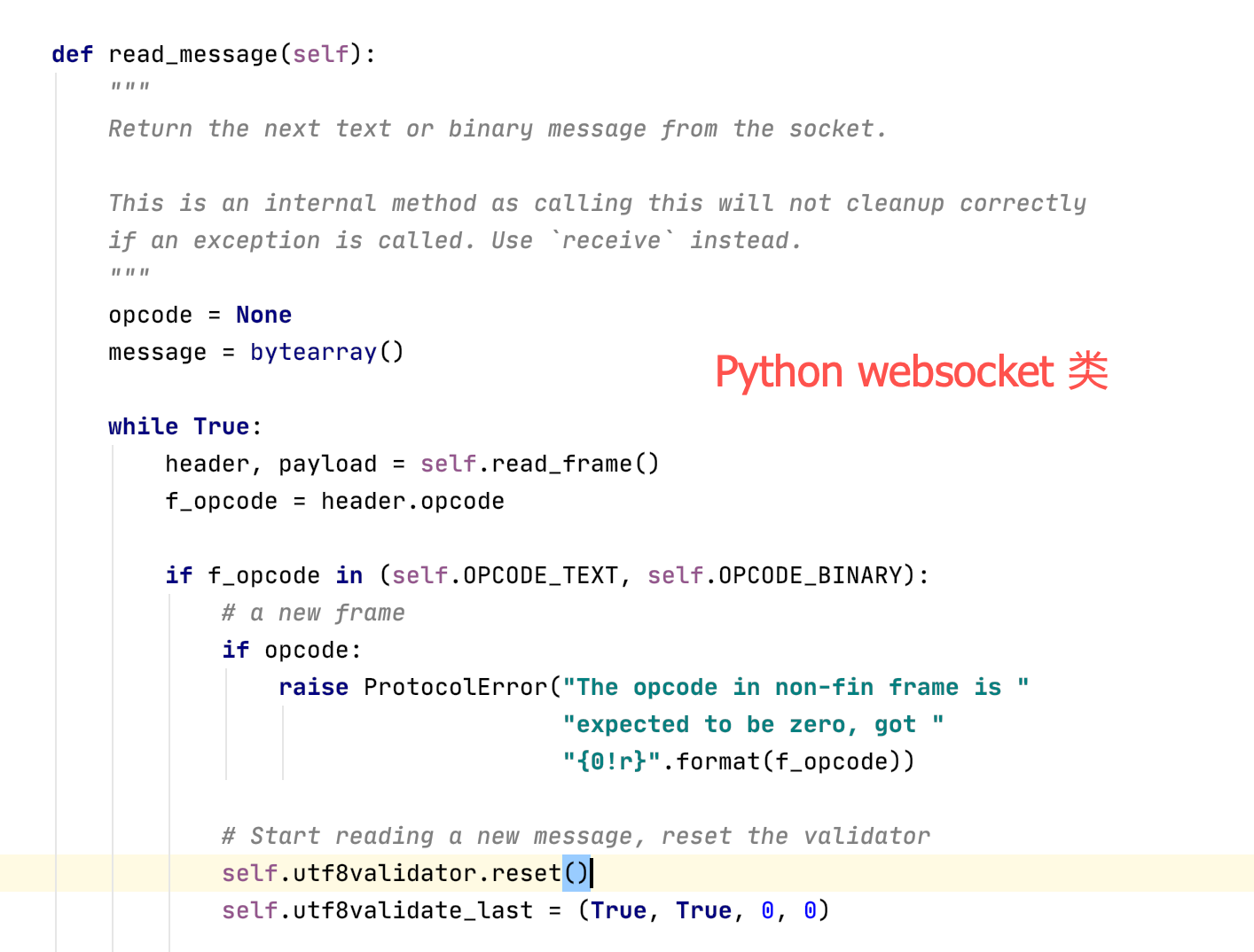
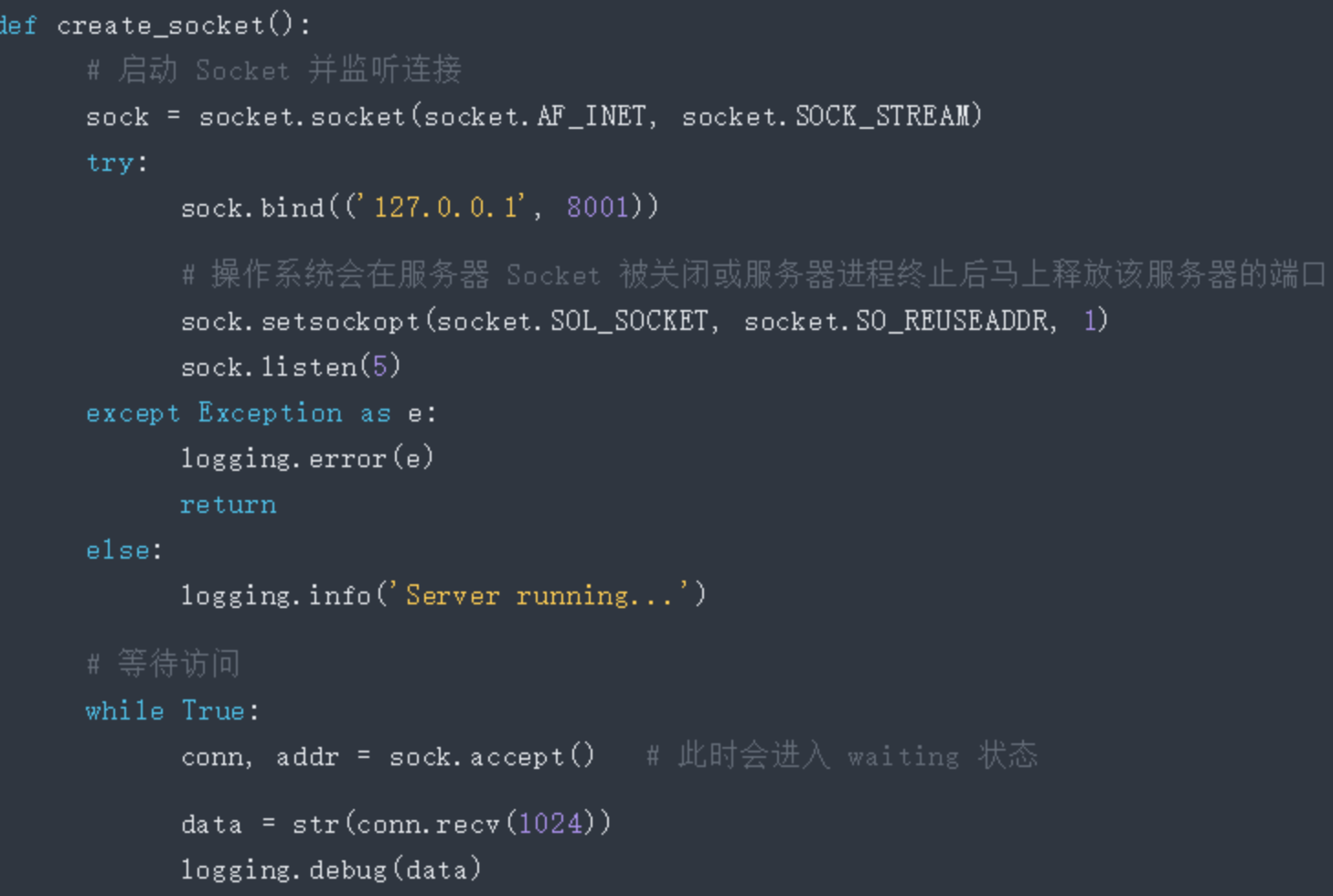
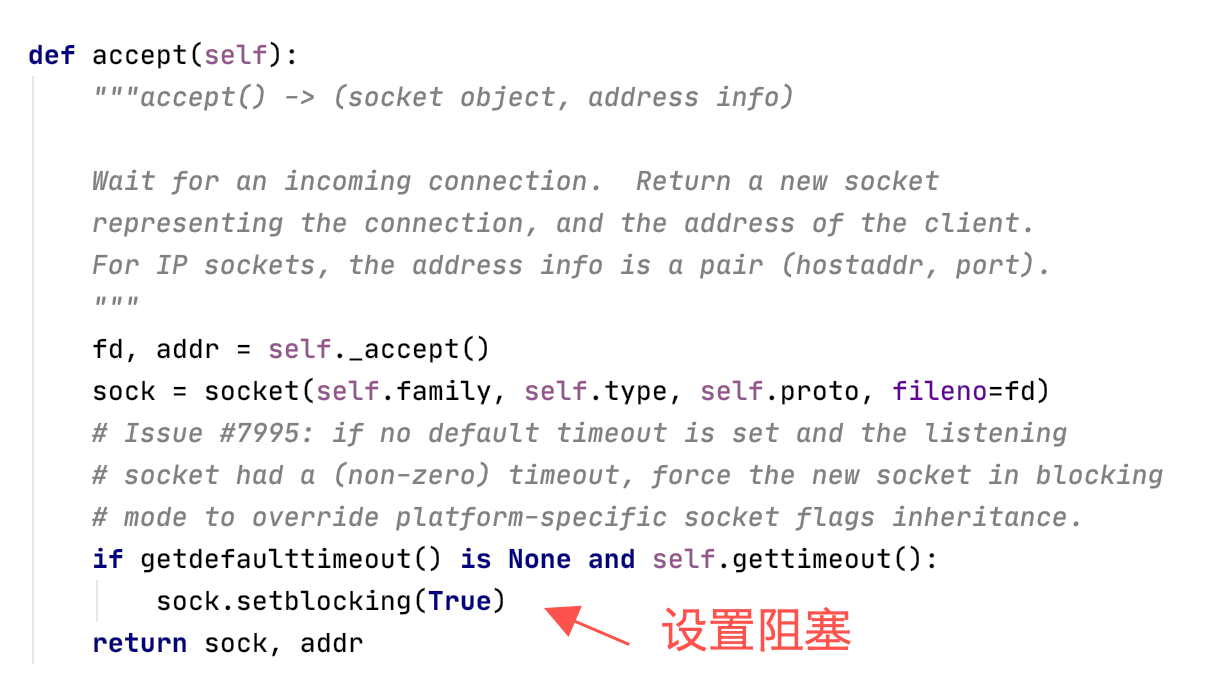
基于这一点,实际上我们可以直接在while True中插入想要执行的代码,等待客户端主动请求(比如查表、激活其他函数等)。
3、关于小程序的开发
其实小程序也就js一个难点,JavaScript的闭包和异步搞清楚了,实际写起来也没那么难。不过这也是仅仅针对简单前端的说法,更复杂的设计还是需要渲染层和解析层相结合的(比如拟物化),这些目前鄙人暂时还无能为力,最多也只能达到一个读懂代码的阶段,还需要多加学习。
js本质还是一条衔尾蛇,promise的用法是其核心:先有promise才有then(),先有resolve()+reject()才能return;前后顺序不能仅仅凭借代码先写还是后写来确定,而是需要探索每个子任务执行的流程。
倒计时模块,典型的递归调用:
| JavaScript
countDown:function(){ if (this.data.count_time == 1){ tt.exitMiniProgram({ success (res) { console.log(`${res}`); }, fail (res) { console.log(`exitMiniProgram 调用失败`); } }); return true } console.log(this.data.count_time) this.setData({ count_time : this.data.count_time - 1 }); setTimeout(this.countDown, 1000); }, |
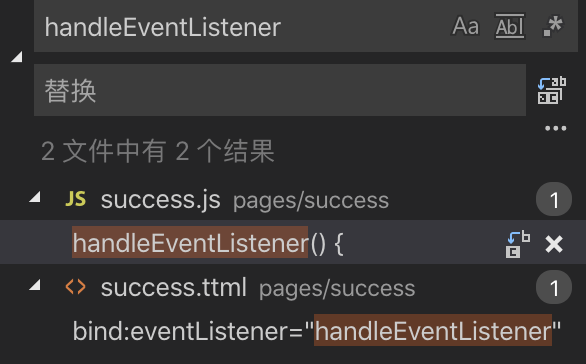
跨组件信息传递,这应该算一个老生常谈的话题了;子组件通过<组件名></组件名>的方式被引用到父页面中,此时我们可以在父组件的引用界面中加上「bind:eventListener="动作监听名称"」,这样子组件的动作父页面的js也可以接收到:
4、硬件相关
个人认为最好还是安卓端直接开发吧,毕竟谷歌安卓api里有直接和串口通讯的方法,已经集成进安卓系统了,如果是通过上图中的方法,还得起一个中台……到时候估计还得请安卓开发大佬协助。
六、刷卡机硬件网络通讯的逆向工程
推荐一款网络通信监听神器:wireshake,这个软件可以拦截「你发出去&访问你」的全部数据包,并且事无巨细地告诉你头文件里每一段数据是什么意思:
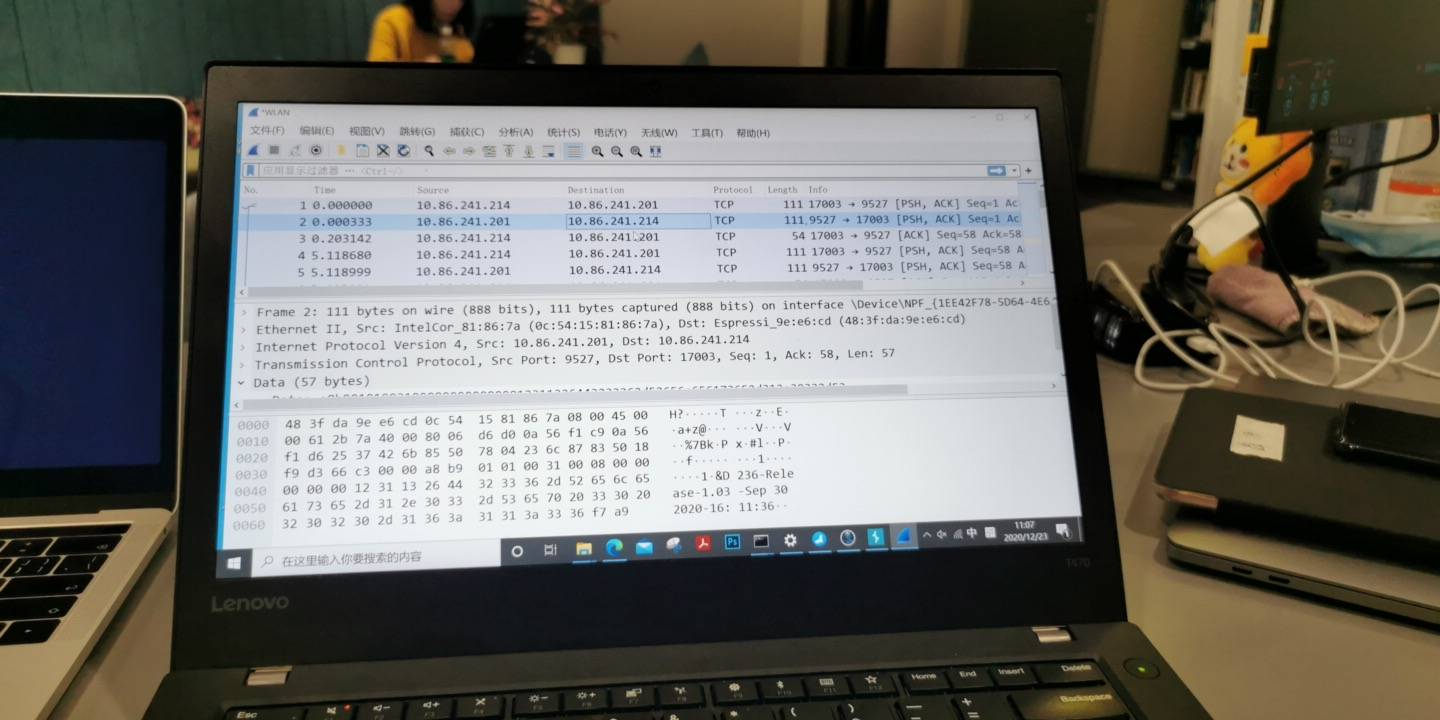
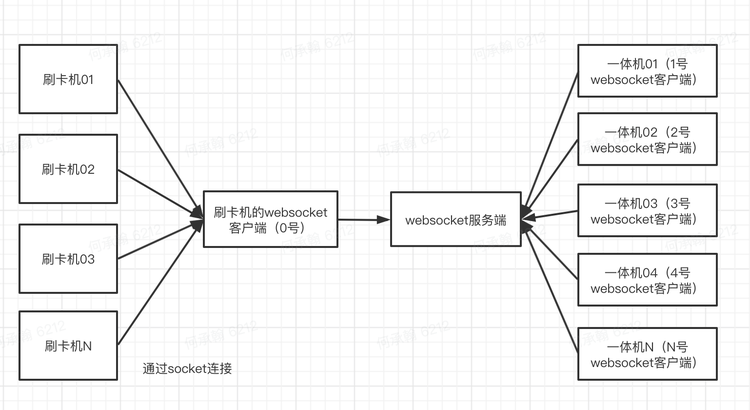
通过这个,我就摸出了读卡器网络交互的大致逻辑:通上电开机后自动连设定好的wifi→每隔三秒轮询一次服务端是否打开→服务端打开后,会完整返回客户端(读卡器)发来的二进制data→客户端每隔1秒进行一次心跳检测(data为:时间+id+固件号)→刷卡时,客户端会即时返回设备id和反序列卡号→服务端接收到这些后会转发给真正的jira服务端以创建工单
于是乎直接通过一个简单的socket通信脚本就完成了中转(相当于伪造一个服务中台,使得所有的读卡器共用此中台),如之前对websocket的解释,这也是阻塞监听。
| Ruby
class Reader(object): def __init__(self): self.host = '0.0.0.0' self.port = 端口 self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) self.sock.bind((self.host, self.port)) self.sock.listen(10)
def run(self): while True: client, addr = self.sock.accept() sentence = client.recv(BUFSIZE) # 具体执行的操作 # …………………… client.sendall(sentence) client.close() |
接着就是验证后的开发与部署:服务台一体机 产品文档
最终效果如下:
※简易python高性能server:
※基础python类框架:
※pymsql封装类:
*redis封装类:
七、配件助手小程序
这个还是更考验前端能力,但因为个人这方面没怎么系统学习过,之前做也是各种抄各种搬别人的代码,甚至有些组件还得找外援(指隔壁data部门的研发朋友)帮忙……以及原本字节只有一个小程序(https://microapp.byte\dance.com/)的,后来因为业务划分多了一个(https://open.feishu.cn/document/uYjL24iN/ucDOzYjL3gzM24yN4MjN)……然后两者有些差异,但差异不大,还可以继续用以下工具开发(现在不行了):

其实小程序作为前端也分展示端和前端逻辑两大部分,展示端主要由html和css构成,布局和普通html5类似,但是有一些细微的不同:比如view→div,text→p等等……最开始做的时候基本都是懵逼的,既要保全原先做的售货机应用不受干扰,又要保证新服务稳定运行,其中还包括大量的前端逻辑,比如对数据做划分,接口uri、请求方式、header&data都要做方法封装……所以最初就需要比较完整的工程构思,其实个人感觉还是js基础用的比较多,花了很多时间补习基础了。
基本上很多都是在搬运API,由于不同的系统运行在不同的平台上,所以数据迁移也是很麻烦的事情。很多时间也花在这个上边了,如果这些系统能统一起来,感觉开发效率会上升。后来用uni-app开发了,有了人家现成的框架和ide,开发提速了不少。
相关文档:
JAX 项目
八、EI项目交接