










使用librosa库实现100行代码制作音乐卡点视频
平台:windows 10 家庭中文版
ide:pycharm
环境:3.7
数字信号处理技术:≈0
librosa库
LibROSA is a python package for music and audio analysis. It provides the building blocks necessary to create music information retrieval systems.
librosa是处理音频的python库,可以进行时频处理、特征提取、绘制声音图形等
官方地址:http://librosa.github.io/librosa
生产流程
1.音频分析:通过对音频的一系列分析取得需要更换图片的时值组(重要,但对于没接触过数字信号处理的小白来说毫无思路)
很不幸,数字信号处理技术≈0,因此在本人深耕数字信号处理技术好几个小时后,有了这不太成熟的代码片段,文中代码因本人基础不好可能有部分错误,望指正
音频分析一般流程
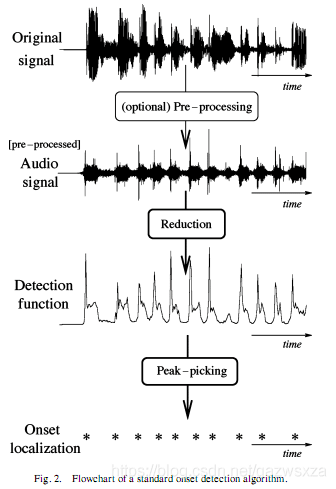
主要函数:
# 音频路径
music_path = ''
# 音频开始截取时间
start_time = 67
# 截取时长
duration = 15
# 采样率
sr=44100
# 加载音频文件
y ,sr= librosa.load(music_path, offset=start_time, duration=duration,sr=sr)
onset_env = librosa.onset.onset_strength(y=y, sr=sr,
hop_length=512,
aggregate=np.median)
# 获取信号中的峰值
# delta参数对取值影响较大
# 这个方法参数较为重要,可以写一个公式计算出部分参数的取值
peaks = librosa.util.peak_pick(onset_env, 1, 1, 1, 1, 0.8, 5)
# 使用beat_track函数得到速度和节拍点
tempo, beats = librosa.beat.beat_track(y=y, sr=sr)
# # 使用plp函数得到脉冲曲线
# pulse = librosa.beat.plp(onset_envelope=onset_env, sr=sr)
# # 得到局部脉冲的最大值
# beats_plp = np.flatnonzero(librosa.util.localmax(pulse))
# 创建一个节拍值1/4、2/4、3/4、4/4的数组
M = beats * [[1 / 4], [2 / 4], [3 / 4]]
M = M.flatten()
M = np.sort(M)
# 局部脉冲与节拍点做10%的去误差,得到节奏点
L = []
for i in M:
for j in peaks:
if i * 0.9 < j < i * 1.1:
L.append(j)
L = list(set(L))
L.sort()
# 节奏点转化为时间
# 取前30个点,不够30个则全取
if len(L) > 30:
point_list = librosa.frames_to_time(L[:30], sr=sr)
else:
point_list = librosa.frames_to_time(L[:len(L)], sr=sr)
# 音乐裁剪,设置开始结束时间
end_time = point_list[len(point_list) - 1] + start_time
start_time = start_time * 1000
end_time = end_time * 1000
sound = AudioSegment.from_mp3(music_path)
word = sound[start_time:end_time]
# 音乐储存路径
word.export('movie/music.wav', format="wav")
movie_cut(point_list)
2.图片处理,转换视频:此处选择先将图片处理成指定大小,然后根据时值将图片转换为特定时长的视频片段,最后将视频合成
遗留问题
1.不能通过代码判断出哪段音乐更适合卡点
2.人声影响较大,尤其是连续的节奏较快的高音
解决思路
深耕数字信号处理技术
librosa:http://librosa.github.io/librosa
源代码:https://github.com/LaoADe/music_point
https://blog.csdn.net/weichen090909/article/details/95666298?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
百万点赞怎么来?Python批量制作抖音的卡点视频原来这么简单!
1
目 标 场 景
玩抖音的朋友都应该知道,最近「卡点视频」简直不要太火。抖音上很多大神也出了剪辑各种卡点视频的教程。
实际上,利用很多手机 APP 或者 PR、FCPX 软件也可以制作卡点视频,但是剪辑效率都太慢。如果想实现一篮子剪辑素材,通过运行一段代码,得到一个卡点视频,这种感觉不要太爽。
本篇文章的目的是利用 Python 从一篮子素材中快速地剪辑卡点小视频这一操作。
2
准 备 工 作
首先,对视频的剪辑需要用到「opencv」库,通过 pip3 安装到虚拟环境中。
# opencv 用于剪辑视频
pip3 install opencv-python然而,通过 opencv 剪辑的视频只有画面,没有背景音乐。
我们需要借助「ffmpeg」,将抖音下载好的某个卡点视频利用 ffmpeg 命令分离出音频文件,然后合并到上面剪辑的视频当中。
# 分离BGM、合并视频和BGM
pip3 install ffmpeg3
编 写 脚 本
我们以抖音上的某个卡点音乐为例,这段背景音乐的节奏需要一个 2s 的视频,然后其他都是静态图片,每个图片显示 0.5s。
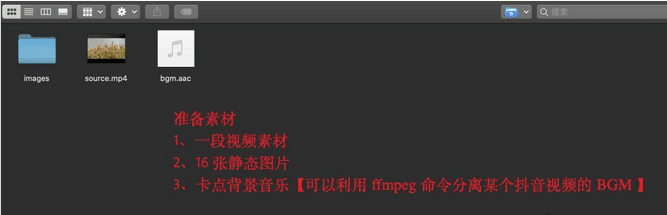
下面通过 5 个步骤完成卡点视频的剪辑,分别是:剪辑开始视频、合并静态图片视频、合并上面两段视频、给视频加入水印、加入背景音乐。学习过程中有不懂的可以加入我们的学习交流秋秋圈784中间758后面214,与你分享Python企业当下人才需求及怎么从零基础学习Python,和学习什么内容。相关学习视频资料、开发工具都有分享
第一步,我们需要从视频素材文件中剪辑一段 2s 的片段。
通过 cv2 库为视频文件构建一个「VideoCapture」对象,然后获取到视频的帧率和视频的分辨率。
# 视频源
videoCapture = cv2.VideoCapture(soure_filename)
# 获取视频的帧率
fps = videoCapture.get(cv2.CAP_PROP_FPS)
# 获取视频的分辨率
img_size = (int(videoCapture.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(videoCapture.get(cv2.CAP_PROP_FRAME_HEIGHT)))然后,利用上面的帧率、分辨率构建一个写入对象,即:「VideoWriter」。
# 构建一个视频写入对象
video_writer = cv2.VideoWriter(output_filename, cv2.VideoWriter_fourcc('X', 'V', 'I', 'D'), fps, img_size)最后,通过传入要开始剪辑的起始点和要剪的长度,然后循环读取视频帧,如果满足条件,就写入到目标视频文件中。
写入视频帧完成之后,需要手动释放对象资源。
# 开始帧和结束帧
start_frame = fps * start_time
end_frame = start_frame + peroid * fps
# 循环读取视频帧,只写入开始帧和结束帧之间的帧数据
while True:
success, frame = videoCapture.read()
if success:
i += 1
if start_frame <= i <= end_frame:
# 将截取到的画面写入“新视频”
video_writer.write(frame)
else:
break
# 释放资源
videoCapture.release()第二步,需要把所有的静态文件都合成一段视频。
ps:**为了保证每一张****静态图片都显示 0.5s,并且静态图片生成的视频与第一段视频使用同一帧率,因此我们应该针对每一张图片写入多次,即多帧数据。**每张图片写入的总次数为上段视频的帧率的 1/2。
和剪辑视频类似,静态图片合成视频也需要先构建一个写入对象 VideoWriter,然后通过向上取整获取要写入的总帧数。
# 视频格式:MP4
fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
# 构建写入对象
video = cv2.VideoWriter(output_video_path, fourcc, fps, img_size)
# 每一张图片要写入的帧数目
total_count = math.ceil(fps / 2)另外需要注意的是,为了保证图片合成的视频能与第一段视频顺利剪辑在一起,这里需要对图片的分辨率进行缩放,没有像素的位置填充为黑色。
def resize_image(target_image_path, target_size):
"""
调整图片大小,缺失的部分用黑色填充
:param target_image_path: 图片路径
:param target_size: 分辨率大小
:return:
"""
image = Image.open(target_image_path)
iw, ih = image.size # 原始图像的尺寸
w, h = target_size # 目标图像的尺寸
scale = min(w / iw, h / ih) # 转换的最小比例
# 保证长或宽,至少一个符合目标图像的尺寸
nw = int(iw * scale)
nh = int(ih * scale)
image = image.resize((nw, nh), Image.BICUBIC) # 缩小图像
# image.show()
new_image = Image.new('RGB', target_size, (0, 0, 0, 0)) # 生成黑色图像
# 将图像填充为中间图像,两侧为灰色的样式
new_image.paste(image, ((w - nw) // 2, (h - nh) // 2))
# 覆盖原图片
new_image.save(target_image_path)图片分辨率处理完成之后,最后就可以读取指定文件夹下的图片,按照上面获取的次数把静态图片写入到视频文件中。
# 使用opencv读取图像
frame = cv2.imread(image_path)
# 直接缩放到指定大小
frame_suitable = cv2.resize(frame, (img_size[0], img_size[1]), interpolation=cv2.INTER_CUBIC)
# 把图片写进视频
# 重复写入多少次
count = 0
while count < total_count:
video.write(frame_suitable)
count += 1以上两步已经完成了两段单独视频的剪辑,第三步是「合成」上面的两段视频。
由于两段视频的帧率、分辨率都一致,这里不需要做其他多余的处理,只需要遍历两段视频文件,循环读取每一帧,然后写入到新的视频文件中。
第四步,需要对视频添加「水印」操作。
添加水印也很方便,利用 cv2 中的函数 putText,指定水印的起始坐标、字体样式、字体大小和颜色,然后循环每一帧,写入到视频就可以实现。
ret, frame = cap.read()
while ret:
# 文字在图中的坐标(注意:这里的坐标原点是图片左上角)
x, y = img_size[0] - 200, img_size[1] - 50
# 写入水印文字,文字颜色为白色
cv2.putText(img=frame, text=mask_word,
org=(x, y), fontFace=cv2.FONT_HERSHEY_COMPLEX_SMALL,
fontScale=1, color=(255, 255, 255))
video_writer.write(frame)
ret, frame = cap.read()
# 删除源文件,并重命名临时文件
os.remove(video_path)
os.rename(video_temp_path, video_path)
print('水印添加完成~')
video_writer.release()
cap.release()最后一步就是合成视频和背景音乐,重新生成一段视频文件。
利用视频的帧率与总帧数得到视频的总时长,然后利用 ffmpeg 命令对背景音乐做一次裁剪操作,使得视频的长度与背景音乐的时间长度一致。学习过程中有不懂的可以加入我们的学习交流秋秋圈784中间758后面214,与你分享Python企业当下人才需求及怎么从零基础学习Python,和学习什么内容。相关学习视频资料、开发工具都有分享
#获取视频的长度
cap = cv2.VideoCapture(video_path)
#帧率
fps = cap.get(cv2.CAP_PROP_FPS)
#总帧数
frame_count = cap.get(cv2.CAP_PROP_FRAME_COUNT)
#视频总时长-秒,这里做取整操作 【浮点类型】
time_count = math.floor(frame_count / fps)
print('帧率:%f,总帧数:%d' % (fps, frame_count))
print(time_count)
# 3.截取音频
# 为了简单,这里一般不会超过一分钟
bgm_temp_path = get_temp_path(bgm_path, 'temp_new')
os.system('ffmpeg -i %s -ss 00:00:00 -t 00:00:%d -acodec copy %s' % (bgm_path, time_count, bgm_temp_path))接着使用 ffmpeg 命令,合并视频文件和音频文件,就可以生成一个我们需要的卡点视频。
#视频、音频合二为一
# 临时文件
video_temp_path = get_temp_path(video_path, 'temp')
os.system('ffmpeg -i %s -i %s -vcodec copy -acodec copy %s' % (video_path, bgm_path, video_temp_path))
# 删除源文件,重命令临时文件
os.remove(video_path)
os.rename(video_temp_path, video_path)4
结 果 结 论
运行程序后,视频、图片、背景音乐会自动进行剪辑、合成,最后加上水印,在本地生成一个卡点视频。