










IFTTT 的技术架构
Data is essential for IFTTT. Our BD and marketing team rely on data to make critical business decisions. The product team relies on data to test to understand when users are using my product to make product decisions. The data team itself relies on data to build products, such as the recipe recommendation system and spam detection tools. In addition, our partners rely on data to obtain the performance of Channels in real time.
Because data is so critical to IFTTT, and our services handle billions of events every day, our data infrastructure must be highly scalable, usable, and resilient to keep up with rapid iterations of products. In this article we will take you through the data infrastructure and architecture, and also share some of the gains we have made in building and operating data.
Data Sources
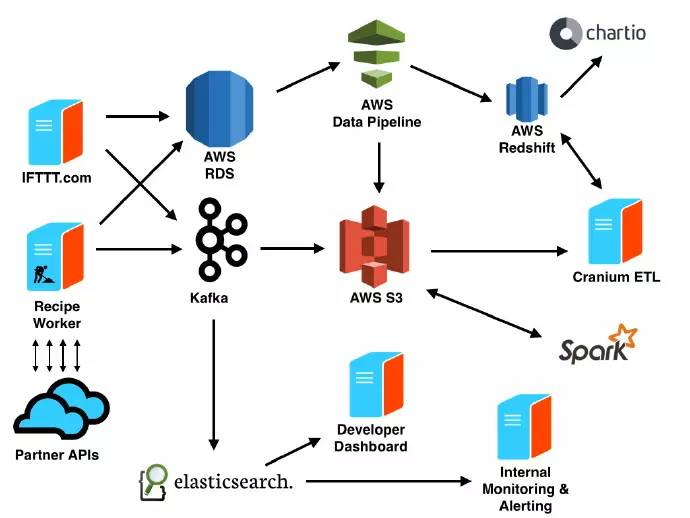
There are three sources of data in IFTTT, which are crucial for understanding user behavior and the efficiency of Channels.
First, there is a MySQL cluster in AWS RDS to maintain the current state of the basic content of the application, such as users, channels, and recipes, including their relationships. IFTTT.com and mobile applications are supported by Rails applications. Get the data and export it to S3, and use AWS Data Pipline to import to Redshift every day.
Next, like user interaction data with IFTTT products, we collect event data from the Rails application to the Kafka cluster.
Finally, to help monitor the behavior of thousands of partner APIs, we collect information about API requests generated by workers when running recipes, including response time and HTTP status codes, which are imported into the Kafka cluster.
Kafka by IFTTT
We use Kafka as the data transmission layer to achieve decoupling between data producers and consumers. In this architecture, Kafka acts as an abstraction layer between producers and consumers in the system, rather than pushing data directly to consumers. Producers push data to Kafka, and consumers read data from Kafka. This makes adding new data consumers more loose.
Because Kafka acts as a log-based event stream, because consumers track their own position in the event stream. This allows consumer data to be switched between two modes: real-time and batch. It also allows consumer data to reprocess the data they previously consumed, which is helpful if the data needs to be reprocessed in the event of an error.
Once the data is in Kafka, we use it in various locations. Consumers of batch data put a copy of the data into S3 in batches every hour. Consumers of real-time data will send the data to the Elasticsearch cluster, and we hope that the library will be open source as soon as possible.
Business Intelligence
Use Cranium (internal ETL platform) to transform and normalize the data in S3 to AWS Redshift. Cranium enables us to write ETL jobs in SQL and Ruby. It defines the dependencies between these tasks and schedules their execution. Cranium supports data visualization reports (using Ruby and D3), but most data visualization uses Chartio. We found that Chartio is very intuitive for people with limited SQL experience.
People in projects, businesses, and even communities can use these data to solve problems and discover new points.
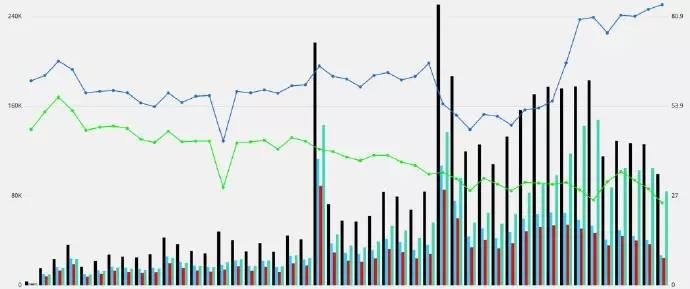
Data visualization with Chartio
Machine learning
We use some advanced machine learning techniques to ensure that IFTTT users have a good experience. For Recipe's recommendation and abuse detection, we use Apache Spark running on EC2 and S3 as data storage. More content will be explained in a future blog post.
Real-time monitoring and alarm
API events are stored in Elasticsearch for real-time monitoring and alarming. We use Kibana to visualize the real-time performance of worker processes and the API performance of our partners.
IFTTT partners visit the Developer Channel (trigger this channel when there is a problem with their API). They can use Developer Channel to create recipes and choose different ways (SMS, Email, Slack, etc.) to notify partners.
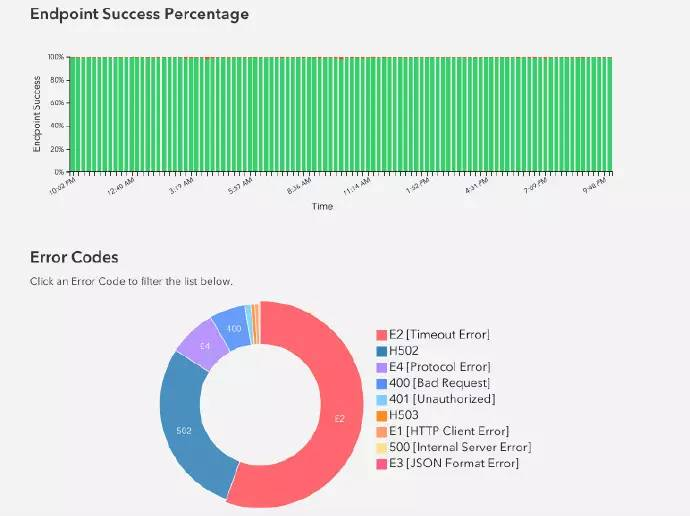
On the developer dashboard, partners can access real-time logs and visualize their Channel health. It is better to use Elasticsearch. In addition, it provides developers with powerful analysis capabilities to help developers understand who is using their Channel and how to use it.
experience
We have summarized some experiences from the development of data infrastructure masters:
By using a data transmission layer like Kafka to separate producers and consumers, the data pipeline is more flexible. For example, a few slow consumers will not affect the performance of other consumers or producers.
Start in a cluster mode from the beginning of the day, which allows you to scale easily. But before expanding the cluster, determine what the performance bottleneck is. For example, if the shard is very large in Elasticsearch, adding more nodes will not help increase the query speed. You have to reduce shard.
In complex systems, appropriate alarms should be given in some places to ensure that everything is normal. We use Sematext to monitor Kafka clusters and consumers. We also use Pingdom to monitor and Pagerduty to alarm.
In order to fully trust your data, it is very important to automatically verify the data. For example, we have developed a service to compare the table in production with the table in Redshift. If there is an exception, an alarm will be given.
Use a date-based folder structure (YYYY/MM/DD) to store event data persistently (S3 in our example). This way storage is easy to handle. For example, if you want to read data for a certain day, you only need to read data from a directory.
Similar to the above, create a time-based index (for example: hourly) in Elasticsearch. If you query all API errors in the last hour in Elasticsearch, you can use simple indexing to improve efficiency.
Instead of submitting independent events, submit events in batches (based on time periods or a large number of events) to Elasticsearch. This helps limit IO.
According to the running data and the type of query, optimize the parameters such as the number of Elasticsearch nodes, the number of shards, the maximum value of shard and replication factor.
【Recommendation of WeChat account today ↓】
"ImportNew" is the most popular WeChat public account dedicated to Java technology sharing. Focus on Java technology sharing, including Java basic technology, advanced skills, architecture design and development of Java technology.