










原文:http://kjkfb.pku.edu.cn/info/1061/2293.htm
应用:https://hi.hifiveai.com/#/
项目简介
网络音乐以其使用率一直位居中国互联网应用前三甲的宝座,音乐已经成为用户通过搜索引擎搜索的前三大类内容之一,用户比例高达41.6%,大部分综合搜索引擎都已经提供针对音乐的垂直搜索功能。互联网上日益庞大的用户规模以及海量的数字音乐要求高效的音乐检索手段和令用户满意的检索体验。
本系统采用多模态情感回归的方法,实现音乐情感的自动标注,并通过音乐情感词作为中间桥梁,实现音乐情感维度信息到情感类别的映射,间接实现了音乐情感的分类。因此本系统能够同时满足对音乐情感维度信息和类别信息自动标注的需求。

基于情感的音乐检索界面

基于维度情感模型的检索

基于色彩和情感词的检索
应用范围
音乐情感识别技术自提出以来,经过世界各地大学及研究单位的广泛研究,已经取得了明显的进展。该技术主要应用于需要大规模音乐库的系统场景,如音乐网站、网络电台、手机音乐、车联网系统、云音乐系统、音乐在线商店、音乐数字图书馆、音乐医疗系统、卡拉OK系统、电台音乐点播系统等。
项目阶段
北京大学计算机研究所数字音频实验室对音乐情感识别进行了多年的研究,在学习国内外先进科研成果的同时,我们特别针对中文音乐和歌曲进行了针对性的研究,并对音乐情感识别的各个环节都有新的发展:
1) 完成全部关键算法的研究开发;
2) 完成了基于内容管理技术的音乐库的开发,并集成了情感识别引擎;
3) 在4000首音乐歌曲(音乐:1700首;歌曲:2300首)集上完成情感学习模型的训练;
4) 在5万首音乐歌曲数据库上完成了自动情感标注的测试。
目前本项目已经完成了原型系统的开发,正处在产品化阶段。
知识产权
国外在这一领域的研究已有10年,申请了部分专利,部分产品已经投入应用。这一技术的研究正方兴未艾,我们实验室对这一方向也进行了9年多的深入研究,目前已取得了阶段性的成果,多篇文章发表在国际知名的学术会议上。
合作方式
合作开发、技术转让、技术许可。
使用方法
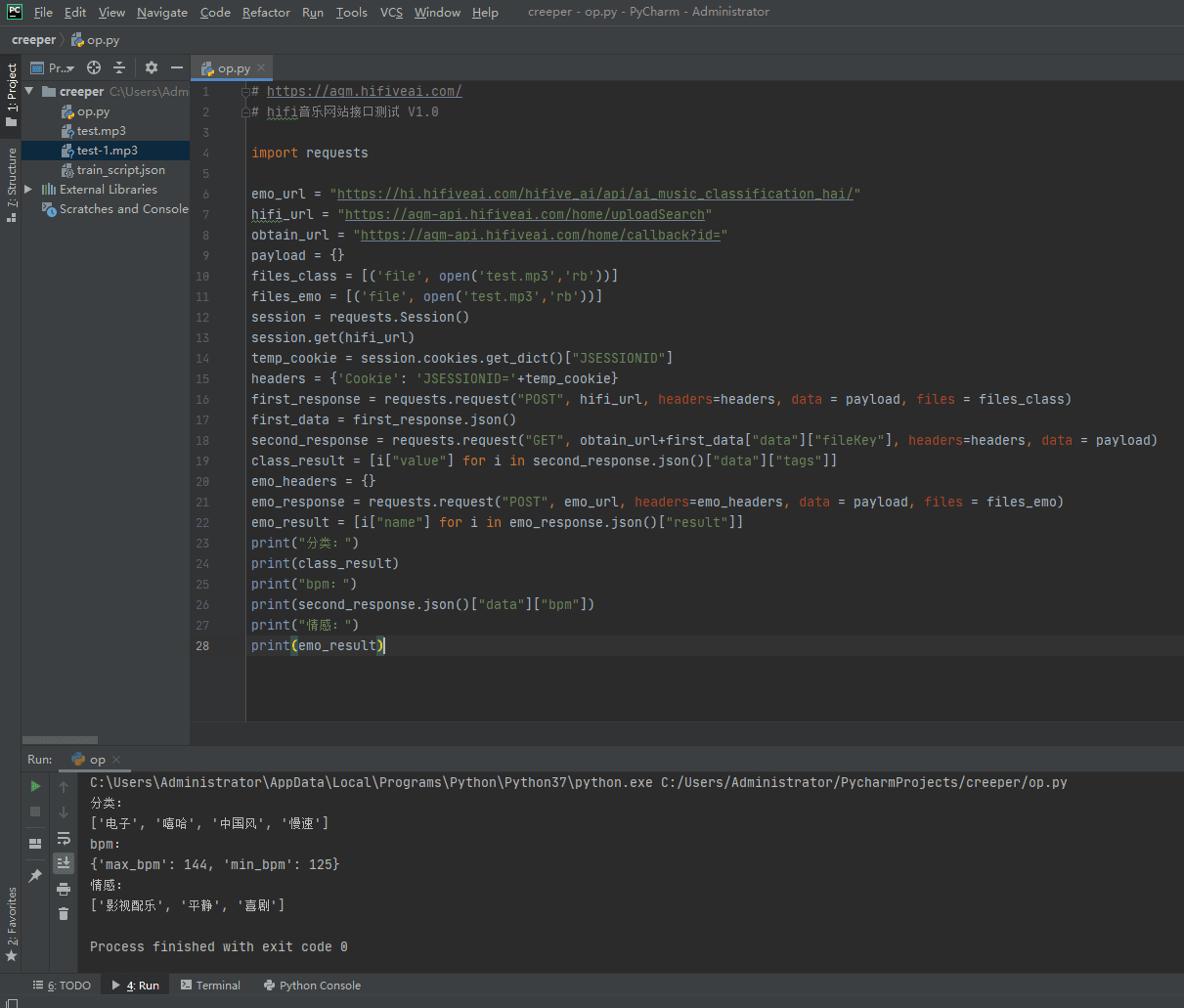
# https://agm.hifiveai.com/
# hifi音乐网站接口测试 V1.0
import requests,time
emo_url = "https://hi.hifiveai.com/hifive_ai/api/ai_music_classification_hai/"
hifi_url = "https://agm-api.hifiveai.com/home/uploadSearch"
hifi_url_token = "https://agm-api.hifiveai.com"
obtain_url = "https://agm-api.hifiveai.com/home/callback?id="
payload = {}
filename = '悲 - 02 - 折剑.mp3'
files_class = {
'file': (filename,open(filename,'rb'),"audio/mp3")
}
files_emo = [('file', open(filename,'rb'))]
session = requests.Session()
session.get(hifi_url_token)
temp_cookie = session.cookies.get_dict()["JSESSIONID"]
headers = {
'Connection': 'keep-alive',
'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,zh-TW;q=0.8,en;q=0.7',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Cookie': 'JSESSIONID='+temp_cookie
}
first_response = requests.request("POST", hifi_url, headers=headers, data = payload, files = files_class)
first_data = first_response.json()
print(first_data)
time.sleep(2)
second_response = requests.request("GET", obtain_url+first_data["data"]["fileKey"], headers=headers, data = payload)
print(second_response.json())
class_result = [i["value"] for i in second_response.json()["data"]["tags"]]
emo_headers = {}
emo_response = requests.request("POST", emo_url, headers=emo_headers, data = payload, files = files_emo)
emo_result = [i["name"] for i in emo_response.json()["result"]]
print("分类:")
print(class_result)
print("bpm:")
print(second_response.json()["data"]["bpm"])
print("情感:")
print(emo_result)